How DeepWiki Works
DeepWiki is an AI agent project, provided by Devin.ai, that generates detailed documentation from a source code repository. Ever since it went viral, I have been curious about how it works.
I combed through online resources and several open-source projects and arrived at a relatively clear picture of the workflow. For the harder parts, I will follow up with my findings in later posts.
Building a Map of the Code Structure
At its core, DeepWiki is a RAG system. It takes a source code repository as input, parses the code, and converts it into two parts: metadata representing the syntactic structure and file structure and vector data representing code descriptions and snippets. The metadata is stored in a relational database, while the corresponding code snippets are stored in a vector database for later LLM retrieval.
Generating WIKI Pages
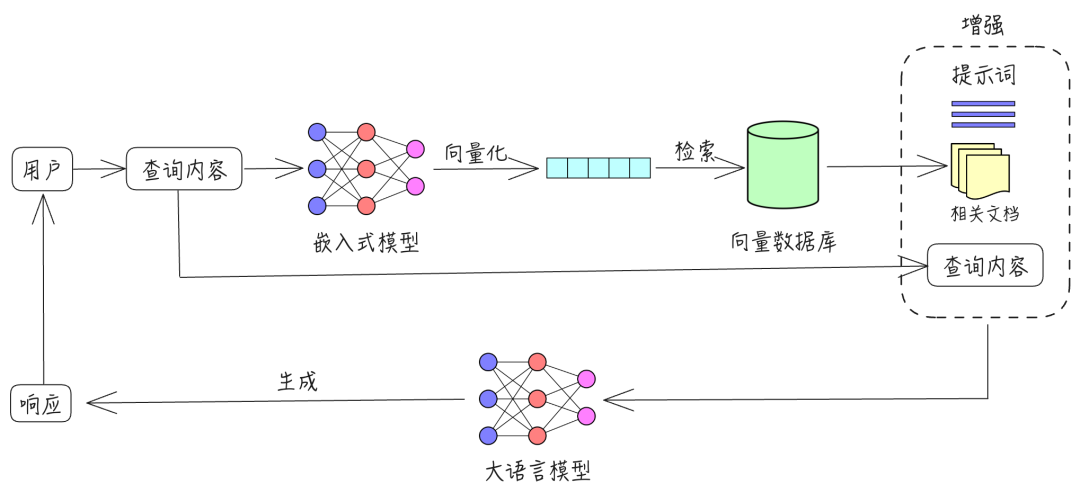
The process of generating a WIKI page is essentially a RAG query:
- The program recursively reads the project structure.
- It queries the metadata database for the current file’s metadata, then searches the vector database for the most relevant code and description IDs.
- It uses those IDs to look up the descriptions in the metadata database, and the corresponding code snippets in the project files.
- It assembles all of the above as context, picks an appropriate prompt based on the metadata type (architecture, components, etc.), and feeds it to the LLM.
- A front-end rendering engine then renders the LLM output into a documentation page.
- Repeat from step 1.
Difficulty 1: The Chunking Strategy
A particularly interesting part of the process above is how to chunk code before embedding. For natural language, chunking is usually based on paragraphs, sentences, and punctuation, so each chunk contains the full context of a sentence or paragraph.
For code, it is different. A function body, for example, is wrapped in { and }. If you tokenize it with a natural-language tokenizer, the context will be split across different chunks, which hurts the accuracy of vector retrieval.
There are currently two approaches. The first is to chunk the whole file. In that case, the file size cannot exceed the chunk-size limit, and the chunks lack the real call-relationship context. We know that the unit of code organization is not the file (the file tree is just a human-friendly organization) — it is a graph of class- and function-level dependencies.
The second approach is to first use a syntax tool to perform static analysis on the code file, and then split the code along the syntactic structure based on the analysis. This is more complex to implement, and I could not find much material on it online. Fortunately, I came across RAG for a Codebase with 10k Repos, which describes how to use static syntax analysis to chunk code and build an efficient RAG system for a code repository. The article does not provide an open-source implementation, though. Considering that this is a core technology of a commercial product, it is well worth digging deeper into. I will keep following this area of research.
Difficulty 2: Parsing the Syntax Structure
Parsing metadata is somewhat simpler than vector data. I found some clues in another open-source project, Repo Graph.
That project uses tree-sitter to analyze the project’s syntax structure and produces three types of metadata files:
tag.json: basic information such as the path, line number, and description of a file, function, or class.tree_structure.json: the project’s file tree structure.*.pkl: a graph of object dependencies.
*.pkl is a graph of object relations that the syntax analyzer obtains by scanning the project’s files, then serializes the Python graph object to disk using the pickle library.
From this implementation, it looks like the embedding process in Difficulty 1 could also use the code metadata generated by tree-sitter to chunk the code by line.
Prompt Engineering
In the RAG query phase, you need to assemble different prompts based on the type of metadata being processed.
The Agent as a Judge project has plenty of prompts worth referencing:
Prompt for generating an overview:
Provide a concise overview of this repository focused primarily on:
* Purpose and Scope: What is this project's main purpose?
* Core Features: What are the key features and capabilities?
* Target audience/users
* Main technologies or frameworks used
Prompt for generating an architecture document:
Create a comprehensive architecture overview for this repository. Include:
* A high-level description of the system architecture
* Main components and their roles
* Data flow between components
* External dependencies and integrations
Prompt for generating a components document:
Provide a comprehensive analysis of all key components in this codebase. For each component:
* Name of the component
* Purpose and main responsibility
* How it interacts with other components
* Design patterns or techniques used
* Key characteristics
* File paths that implement this component
For the rest, please refer to the project files; I won’t enumerate them all here.
Summary
DeepWiki is a code documentation generation tool built on a RAG system. It works through the following steps:
- Perform syntactic analysis on the repository to produce metadata and vector data.
- Query that data through the RAG system to generate documentation.
- Render the results into readable documentation pages with a front-end engine.
There are two main difficulties in implementation:
- The code chunking strategy: it must consider the syntactic structure of the code, not just split it the way you would split natural language.
- Parsing the syntax structure: tools like
tree-sittercan be used to parse the code’s structure.
Although there are some open-source projects to reference, the core chunking strategy implementation still needs to be studied in depth.