《Python源码剖析》第二部分——Python虚拟机基础
Python 执行环境
在编译过程中,这些包含在 Python 源代码中的静态信息都会被 Python 编译器收集起来,编译的结果中包含了字符串,常量值,字节码等在源代码中出现的一切有用的静态信息。在 Python 运行期间,这些源文件中提供的静态信息最终会被存储在一个运行时的对象中,当 Python 运行结束后,这个运行时对象中所包含的信息甚至还会被存储在一种文件中。这个对象和文件就是我们这章探索的重点:PyCodeObject 对象和 pyc 文件。
在程序运行期间,编译结果存在于内存的 PyCodeObject 对象中;而 Python 结束运行后,编译结果又被保存到了 pyc 文件中。当下一次运行相同的程序时,Python 会根据 pyc 文件中记录的编译结果直接建立内存中的 PyCodeObject 对象,而不用再次对源文件进行编译了。
从文章摘录可见,python 生成的不是编译后的文件,而是.py文件对应的静态信息——PyCodeObject,这里包括了字节码指令序列、字符串、常量。每个名字空间(类、模块、函数)都对应一个独立的 PyCodeObject。(python 连编译后的文件里存的都是个对象!)
不被 import 的 py 文件不会生成 pyc。标准库里有 py_compile 等方法也可以生成 pyc。
import 机制 导入某个模块时,先查找对应的 pyc,如果没有 pyc 就生成然后 import 这个 pyc。(所以实际导入的并不是 py 文件,而是 py 文件编译后的 PyCodeObject)。
PyFrameObject Python 程序运行时的「执行环境」。参考操作系统执行可执行文件的过程。Python 也是将函数对应的执行环境封装成栈帧的形式加载进内存。
typedef struct _frame {
PyObject_VAR_HEAD
struct _frame *f_back; //执行环境链上的前一个frame
PyCodeObject *f_code; //PyCodeObject对象
PyObject *f_builtins; //builtin名字空间
PyObject *f_globals; //global名字空间
PyObject *f_locals; //local名字空间
PyObject **f_valuestack; //运行时栈的栈底位置
PyObject **f_stacktop; //运行时栈的栈顶位置
……
int f_lasti; //上一条字节码指令在f_code中的偏移位置
int f_lineno; //当前字节码对应的源代码行
……
//动态内存,维护(局部变量+cell对象集合+free对象集合+运行时栈)所需要的空间
PyObject *f_localsplus[1];
} PyFrameObject;
Python 标准库的sys._getframe()可以动态的在程序执行时获取当前内存中活跃的 PyFrameObject 信息。
LEGB 规则
即 python 作用域的查找顺序是local-enclosing-global-buildin。看下面代码:
a = 1
def g():
print a
def f():
print a //[1]
a = 2 //[2]
print a
g()
代码在[1]处会抛出异常,原因是 python 在编译阶段就把静态数据(局部变量、全局变量、字节码)放入 pyc 里,执行到f()里时,查找到a是在 local 作用域里定义的而不是 global 里,但是此时 local 的 a 还没赋值,所以就会抛出异常。由此可见,python 作用域信息是在静态编译时就处理好了的。
Python 虚拟机运行框架
运行时环境是一个全局的概念,而执行环境实际就是一个栈帧,是一个与某个 Code Block 对应的概念。
在 PyCodeObject 对象的 co_code 域中保存着字节码指令和字节码指令的参数,Python 虚拟机执行字节码指令序列的过程就是从头到尾遍历整个 co_code、依次执行字节码指令的过程。
由上文引用可见,python 在编译阶段将代码块的字节码保存在 PyCodeObject 的 co_code 属性里,然后在执行阶段从头到尾遍历这个 co_code 属性解读字节码。
Python 运行时环境 Python 在运行时用 PyInterpreterState 结构维护进程运行环境,PyThreadState 维护线程运行环境,PyFrameObject 维护栈帧运行环境,三者是依次包含关系,如下图所示:
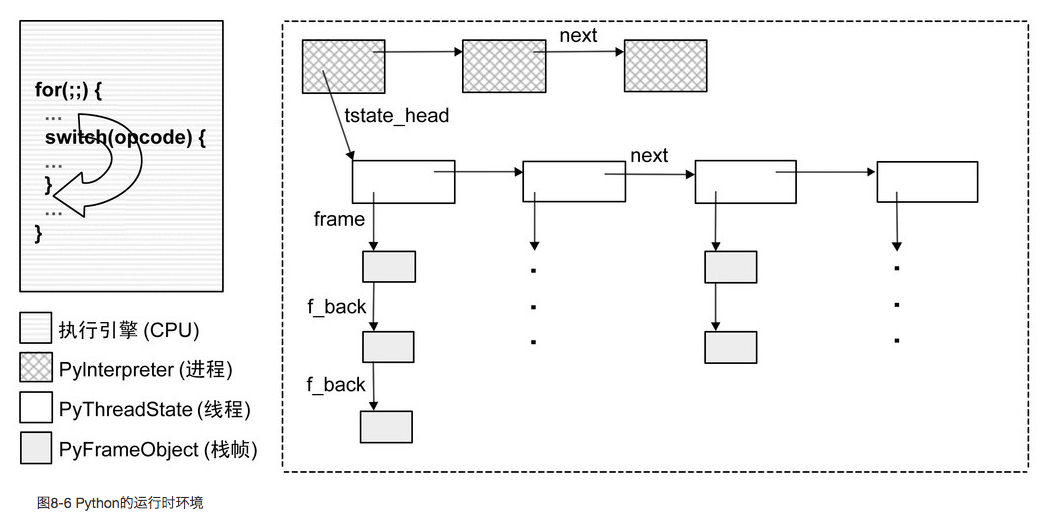
Python 虚拟机就是一个「软 CPU」,动态加载上述三种结构进内存,并模拟操作系统执行过程。程序执行后,先创建各个运行时环境,再将栈帧中的字节码载入,循环遍历解释执行。
Python 字节码
i = 1
0 LOAD_CONST 0 (1)
3 STORE_NAME 0 (i)
例如 python 的一条语句i=1可以解释为下面两行字节码,最左边的第 1 列数字代表这行字节码在内存中的偏移位置,第 2 列是字节码的名字(CPU 并不关心名字,它只是根据偏移量读出字节码,所以这个名字是方便阅读用的),第 3 列是字节码的参数,如LOAD_CONST对应的数据在变量f->f_code->co_consts里,0 就是这个参数位于f->f_code->co_consts的偏移量。最后一列的括号里是从参数里取到的 value。
Python 的异常抛出机制
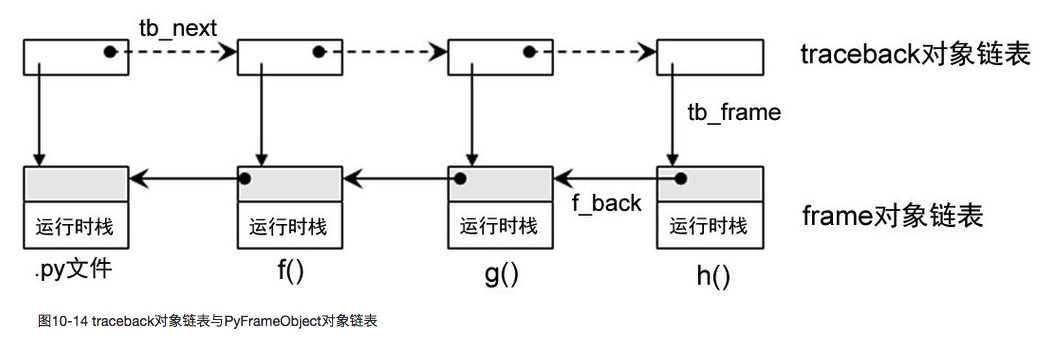
异常处理的操作都在Python/traceback.c文件里,python 每次调用一层函数,就创建改函数对应的 PyFrameObject 对象来保存函数运行时信息,PythonFrameObject 里调用 PyEval_EvalFrameEx 循环解释字节码,如果抛出异常就创建 PyTraceBackObject 对象,将对象交给上一层 PyFrameObject 里的 PyTracebackObject 组成链表,最后返回最上层 PyRun_SimpleFileExFlags 函数,该函数调用 PyErr_Print 遍历 PyTraceBackObject 链表打印出异常信息。
函数对象的实现
PyFunctionObject 是函数对象。在 python 调用函数时,生成 PyFunctionObject 对象,该对象的 f_global 指针用来将外层的全局变量传递给函数内部,然后在ceval.c文件的fast_function里解出 PyFunctionObject 对象里携带的信息,创建新的 PyFrameObject 对象(上文说过这个对象是维护运行时环境的),最后调用执行字节码的函数PyEval_EvalFrameEx执行真正函数字节码。
Python 执行一段代码需要什么? 从书中描述可见,python 执行一段代码需要做几件事:
- 从源码编译出 PyCodeObject 保存变量和字节码
- 执行阶段,从 PyCodeObject 里取出信息交给 PyFrameObject,执行 PyEval_EvalFrameEx 解释字节码
- 如果遇到函数调用,就把函数对应的代码段从 PyCodeObject 存入 PyFunctionObject 对象,然后把这个函数对象通过参数传给新创建的 PyFrameObject ,在内层空间执行 PyEval_EvalFrameEx 解释字节码
- 将结果或异常存入 PyFrameObject 的变量( 异常是存入 f_blockstack 里,外层判断 f_blockstack 里的数据是被 except 捕获还是没有捕获而继续下一步操作) 抛给外层
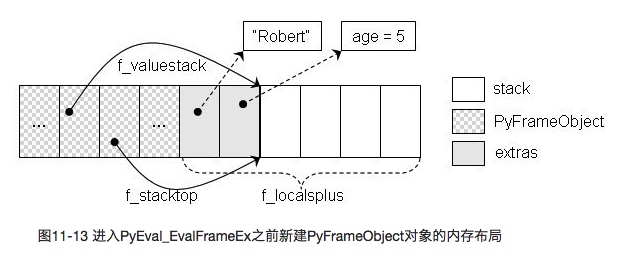
值得注意的是,python 在执行阶段,将对函数参数的键值查找,转换为索引查找,即在转换 PyCodeObject 为 PyFrameObject 时,将参数信息按位置参数、键参数按照一定顺序存储在 f_localsplus 变量中,再用索引来查找对应参数,而需要查找键值。这样提高了运行时效率。下图是foo('Rboert', age=5)在内存中的存储形式。
闭包的实现
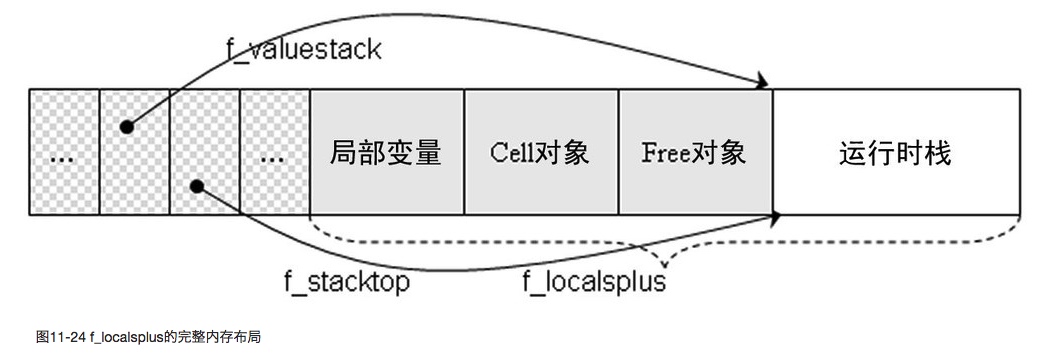
Python 在编译阶段就把函数闭包内层和闭包外层使用的变量存入 PyCodeObject 中:
- co_cellvars:通常是一个 tuple,保存嵌套的作用域中使用的变量名集合;
- co_freevars:通常也是一个 tuple,保存使用了的外层作用域中的变量名集合。
在执行阶段,PyFrameObject 的 f_localsplus 中也为闭包的变量划分的内存区域,如下图所示:
元类
元类<type type>和其他类的关系如下图:
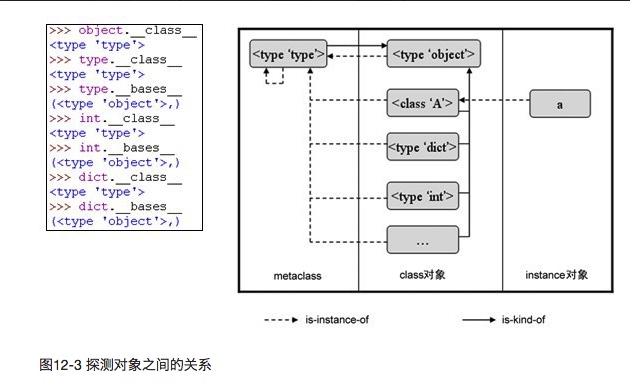
可调用性(callable) ,只要一个对象对应的 class 对象中实现了“call”操作(更确切地说,在 Python 内部的 PyTypeObject 中,tp_call 不为空)那么这个对象就是一个可调用的对象,换句话说,在 Python 中,所谓“调用”,就是执行对象的 type 所对应的 class 对象的 tp_call 操作。
Descriptor
在 PyType_Ready 中,Python 虚拟机会填充 tp_dict,其中与操作名对应的是一个个 descriptor 对于一个 Python 中的对象 obj,如果 obj.class对应的 class 对象中存在get、set和delete三种操作,那么 obj 就可称为 Python 一个 descriptor。
如果细分,那么 descriptor 还可分为如下两种:
- data descriptor : type 中定义了get和set的 descriptor;
- non data descriptor : type 中只定义了get的 descriptor。 在 Python 虚拟机访问 instance 对象的属性时,descriptor 的一个作用是影响 Python 虚拟机对属性的选择。从 PyObject_GenericGetAttr 的伪代码可以看出,Python 虚拟机会在 instance 对象自身的dict中寻找属性,也会在 instance 对象对应的 class 对象的 mro 列表中寻找
- Python 虚拟机按照 instance 属性、class 属性的顺序选择属性,即 instance 属性优先于 class 属性;
- 如果在 class 属性中发现同名的 data descriptor,那么该 descriptor 会优先于 instance 属性被 Python 虚拟机选择

引申:Python 黑魔法 Descriptor (描述器)
- http://www.jianshu.com/p/250f0d305c35
- http://pyzh.readthedocs.io/en/latest/Descriptor-HOW-TO-Guide.html
Bound Method 和 Unbound Method
假设有下面两种对类方法的调用:
class A(object):
def f(self):
pass
a = A()
# [1]
a.f()
# [2]
A.f(a)
# [3]
func = a.f
func()
在代码[1]里,实例 a 调用类方法 f,python 底层会自动完成实例 a 和类方法 f 之间的绑定动作(调用func_ descr_get(A.f, a, A),将实例地址和函数对象 PyFunctionObject 封装到一个 PyMethodObject),而代码[2]里直接通过 A 调用,则 f 为非绑定的 PyMethodObject,里面没有实例信息,需要传入 a。
比较绑定方法与非绑定方法可知,通过[1]的方式每次都要绑定一次实例,开销非常大,下图比较的是[1]和[3]两种方式,绑定操作的执行次数。
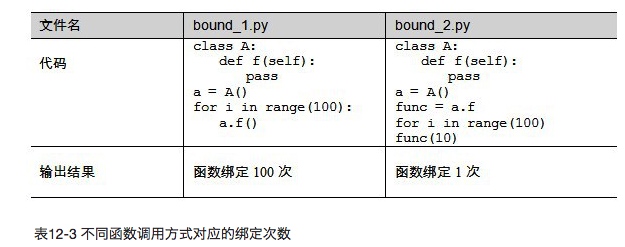
结论: 调用类实例绑定的方法时,如果方法执行次数非常多,最好将方法赋值给一个变量,防止重复绑定增加开销