《Python源码剖析》第三部分——Python虚拟机进阶
Python 环境初始化
进程启动后创建 PyInterpreterObject,PyInterpreterObject 里面维护了全局 module 映射表interp->modules,该表默认初始化为buildin模块,
Python 的 import 机制
Python 虚拟机在执行“import A”时,会为 package A 创建一个 module 对象,同时会在该 module 维护的 dict 中添加两个表示元信息的属性:name和path。而 Python 虚拟机从 A/init.py 中执行“import mod1”时,也会为 mod1 创建一个 module 对象,同时也会设置name属性,但是这时就不设置path属性了。
package 是由 module 聚合而成。更清楚的表述是:module 属于一个 package。我们不能说,module1 属于 module2。我们前面已经看到,module 的路径实际上是一种树状结构,从图 14-11 中可以看到,在这个树状结构中,module 的父节点只能是 package,而不可能是另一个 module。
GIL
Python 虚拟机使用一个全局解释器锁(Global Interpreter Lock,GIL)来互斥线程对 python 虚拟机的使用。
注意这里 GIL 是解释器一级的互斥锁,也就是同一时间只能有一个线程占用 python 解释器。所以GIL 是用来让操作系统中分配的多个线程互斥的使用 python 解释器的,是建立在系统线程调度基础之上的一套 C API 互斥机制,是比操作系统线程资源更大粒度的锁。
Python 的线程是基于操作系统原生线程的,所以 python 的线程不是「虚拟出来的」。
那么究竟 Python 会在众多的等待线程中选择哪一个幸运儿呢?答案是,不知道。没错,对于这个问题,Python 完全没有插手,而是交给了底层的操作系统来解决。也就是说,Python 借用了底层操作系统所提供的线程调度机制来决定下一个进入 Python 解释器的线程究竟是谁。
GIL 在 C 里对应的结构:
[thread_nt.h]
typedef struct NRMUTEX {
LONG owned ;
DWORD thread_id ;
HANDLE hevent ;
} NRMUTEX, *PNRMUTEX ;
其中owned初始化为-1,表示锁可用,否则为不可用。thread_id代表线程 id,最后一个是平台相关的变量,win32 上是一个 event 内核对象。
多线程 - 标准调度
当 Python 启动时,是并不支持多线程的。换句话说,Python 中支持多线程的数据结构以及 GIL 都是没有创建的,Python 之所以有这种行为是因为大多数的 Python 程序都不需要多线程的支持
书中指出,由于 python 的多线程标准调度机制是有代价的,所以默认单线程不初始化 GIL。
- 主线程启动后,会用
ident = PyThread_start_new_thread(t_bootstrap, (void*) boot);函数调用操作系统内核接口创建子线程,然后主线程挂起等待obj.done。注意,此时主线程中持有 GIL。 - 主线程等待的这段时间里,子线程将自己的线程 id 等信息设置好,通知内核对象
obj.done,唤醒等待中的主线程。此刻,主线程和子线程都同时由操作系统调度,但是主线程一直持有着 GIL。 - 子线程继续执行后进入 python 解释器,发现需要等待获取 GIL。此时子线程主动将自己挂起(而不是由操作系统挂起)。这样就进入了两个线程通过 GIL 调度的阶段。
- 主线程被唤醒后,继续执行,直到 python 内置的时钟计时器
_Py_Ticker结束才将自己挂起,让出 GIL(_Py_Ticker会在每次执行一条字节码后自动减 1,初始默认为 100)。
通过上面 4 步,python 的两个线程就完成了从系统调度上升到 python 标准 GIL 调度的流程。
阻塞调度
如同上面流程介绍的,标准调度是 python 使用软件时钟调度线程,那么有时候 python 的线程会自我阻塞,比如raw_input()、sleep()等函数,这时 python 就会使用阻塞调度的方式。
- 主线程调用
sleep(1)后,调用Py_BEGIN_ALLOW_THREADS立刻释放 GIL,然后调用操作系统的 sleep 操作。此时主线程就由操作系统自动管理。 - 子线程拿到 GIL。此时主线程和子线程同时可被操作系统调度。操作系统在执行一段时间子线程后会挂起,调度主线程,发现主线程 sleep 没结束就挂起主线程,就继续唤醒子线程执行。
- 当主线程 sleep 结束,操作系统唤醒主线程。主线程调用
Py_END_ALLOW_THREADS再次申请 GIL,重新进入 python 标准调度流程。
可见 python 在保证线程安全的前提下,允许线程在某些时刻脱离 GIL 标准调度流程。
其中Py_BEGIN_ALLOW_THREADS和Py_END_ALLOW_THREADS两个负责释放和等待 GIL 的宏的实现如下。
[ceval.h]
#define Py_BEGIN_ALLOW_THREADS { \
PyThreadState *_save; \
_save = PyEval_SaveThread();
#define Py_END_ALLOW_THREADS PyEval_RestoreThread(_save); \
}
[ceval.c]
PyThreadState* PyEval_SaveThread(void)
{
PyThreadState *tstate = PyThreadState_Swap(NULL);
if (interpreter_lock)
PyThread_release_lock(interpreter_lock);
return tstate;
}
void PyEval_RestoreThread(PyThreadState *tstate)
{
if (interpreter_lock) {
int err = errno;
PyThread_acquire_lock(interpreter_lock, 1);
errno = err;
}
PyThreadState_Swap(tstate);
}
用户级互斥
用户级的互斥锁利用操作系统的互斥机制实现,同时要考虑防止和 GIL 形成死锁。所以过程与阻塞调度类似需要使用Py_BEGIN_ALLOW_THREADS和Py_END_ALLOW_THREADS这两个宏。
- 线程 a 调用 lock 对象加锁,lock 对象内部调用系统互斥机制,同时执行
Py_BEGIN_ALLOW_THREADS释放 GIL 防止死锁。 - 线程 b 获得 GIL,执行到某处释放锁,lock 对象内部调用系统机制释放锁,同时底层调用了
Py_END_ALLOW_THREADS等待 GIL。 - 线程 a 被系统唤醒,获取 GIL,一气呵成。
子线程的销毁
在线程的全部计算完成之后,Python 将销毁线程。需要注意的是,Python 主线程的销毁与子线程的销毁是不同的,因为主线程的销毁动作必须要销毁 Python 的运行时环境,而子线程的销毁则不需要进行这些动作。
内存管理
大块内存管理直接调用 C 的 malloc 和 free 接口,小块内存分配则由 python 的内存池管理机制调度。
小块内存管理的对象
Python 的内存块叫 block,每个 block 大小不同,都是 8 的整数倍。管理 block 的叫 pool,一个 pool 是 4K。pool 管理相同大小的一堆 block。pool 对象的 szindex 变量保存了这个 pool 对应的 block 大小。
,一个 pool 可能管理了 100 个 32 个字节的 block,也可能管理了 100 个 64 个字节的 block,但是绝不会有一个管理了 50 个 32 字节的 block 和 50 个 64 字节的 block 的 pool 存在
Python 对于内存块的管理类似对象的策略,每次内存分配一整个 block,回收时先将不用的 Block 加入闲置的队列里等待重新利用,不是直接回收。(惰性回收策略)
管理多个 pool 的数据对象是 arena。下图可见,pool 结构是一次性分配好一块内存,而 arena 则是通过指针连向一块 pool。
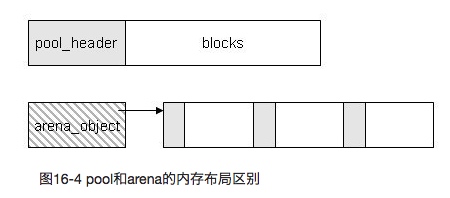
而 python 维护一个名叫 arenas 的数组,数组元素就是 arena 对象。arena 之间通过由两条链表相连。它们分别是:
- unused_arena_objects 是单向量表,指向未分配 pool 的 arena
- usable_arenas 是双向链表,表示已经分配了 pool 的 arena
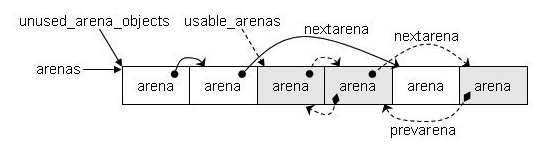
当一个 arena 的 area_object 没有与 pool 集合建立联系时,这时的 arena 处于“未使用”状态;一旦建立了联系,这时 arena 就转换到了“可用”状态。对于每一种状态,都有一个 arena 的链表。“未使用”的 arena 的链表表头是 unused_arena_objects、arena 与 arena 之间通过 nextarena 连接,是一个单向链表;而“可用”的 arena 的链表表头是 usable_arenas、arena 与 arena 之间通过 nextarena 和 prevarena 连接,是一个双向链表。
Pool 是 python 管理内存的对象,arena 虽然更上层,但是 arena 内的 pool 集合可能管理 32 字节的 block,也可能管理 64 字节的 block,所以 arena 无法决定销毁和分配内存。Python 仍然以 pool 为单位管理内存开销。(pool 有 size 概念,arena 没有 size 概念)
Pool 有三种状态 full、empty 和 used。其中 full 不需要连接起来,其他两种状态会被 freepools 和 usedpools 连接起来方便管理。
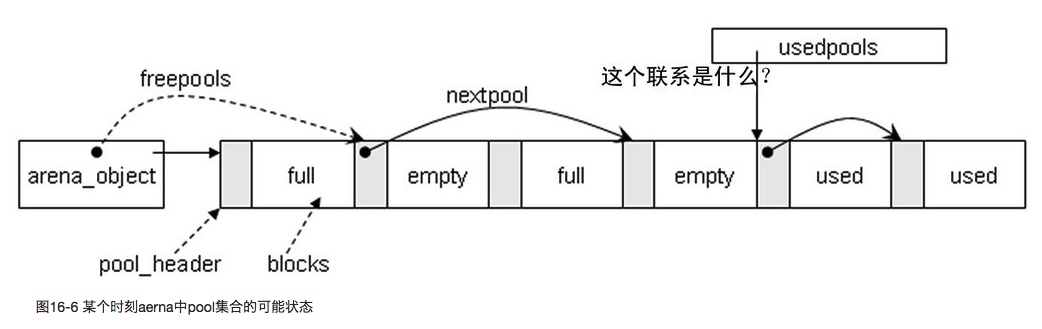
arena 的分配
arena 可以指向 32 位 pool 集合,也可以指向 64 位 pool 集合。分配内存的过程如下:
- 先在 usable_arenas 链表上找可用的 arena,然后找到符合要求的 pool
- 如果没有可用的 arena,则从 arenas 数组里摘下来新的 arena,放在 usable_arenas 里,然后初始化 pool
- 从 usedpools 链表里找可用的 blocks
- usedpools 没有可用的 pool,就从 freepools 链表分配一个 empty 状态的 pool
Python 编译时指定内存上限
当 Python 在 WITH_MEMORY_LIMITS 编译符号打开的背景下进行编译时,Python 内部的另一个符号会被激活,这个名为 SMALL_MEMORY_LIMIT 的符号限制了整个内存池的大小,同时,也就限制了可以创建的 arena 的个数。在默认情况下,不论是 Win32 平台,还是 unix 平台,这个编译符号都是没有打开的,所以通常 Python 都没有对小块内存的内存池的大小做任何的限制。
小块内存管理的流程
(此部分摘自书中代码注释)
- 如果申请的内存小于 SMALL_REQUEST_THRESHOLD,使用 Python 的小块内存的内存池。否则,转向 malloc
- 根据申请内存的大小获得对应的 size class index
- 如果 usedpools 中可用的 pool,使用这个 pool 来分配 block
- 分配结束后,如果 pool 中的 block 都被分配了,将 pool 从 usedpools 中摘除
- 如果 usedpools 中没有可用的 pool,从 usable_arenas 中获取 pool
- 如果 usable_arenas 中没有就“可用”的 arena,开始申请 arena
- 从 usable_arenas 的第一个 arena 中获取一个 pool
- 获取 pool 成功,进行 init pool 的动作,将 pool 放入 used_pools 中,并返回分配得到的 block
- 获取 pool 失败,对 arena 中的 pool 集合进行初始化,然后转入 goto 到 init pool 的动作处,初始化一个特定的 pool
Python 2.5 对多次分配小内存造成内存泄漏的处理
在 2.5 之前版本,Python 的 arena 从来不释放 pool。这就造成反复分配小内存后造成的 arena 太多而内存无法回收。
2.5 之后的处理办法:arena 有两种状态,unused 和 usable。上文已经介绍过。
- 如果 arena 中所有的 pool 都是 empty 的,释放 pool 集合占用的内存。arena 变成 unused 状态,从 usable_arenas 剔除
- 如果 arena 初始化了新的 pool,arena 变成 usable 状态,从 usable_arenas 链表中顺序查找位置插入该 arena。注意,usable_arenas 是有序链表(按照 arena 中 pool 的个数排序,pool 多的 arena 排前边,pool 少的排后边)
- 这样,再有分配内存的请求时,先从 usable_arenas 表头顺序查,排在前边 pool 多的 arena 就被利用的充分,pool 少的 arena 就更有可能变成 unused 状态,容易被释放掉。达到节省内存的目的
内存池全景
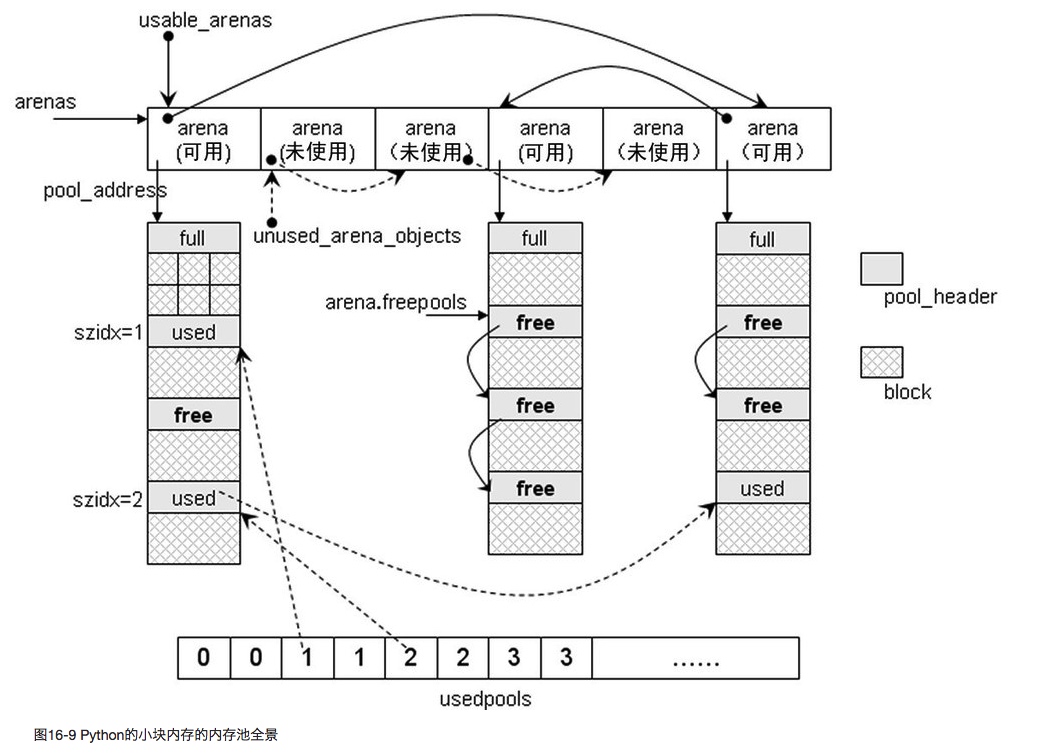
Python 垃圾回收机制
除了计数器,python 还是使用了标记-清除,分代回收机制。
标记 - 清除
三色模型
根据系统内所有对象的引用情况建立有向图,沿着有向图从根开始的逐层染色,黑色代表该节点所有引用都检查过了,灰色表示节点是可达的,当所有灰色节点都变为黑色,检查结束。
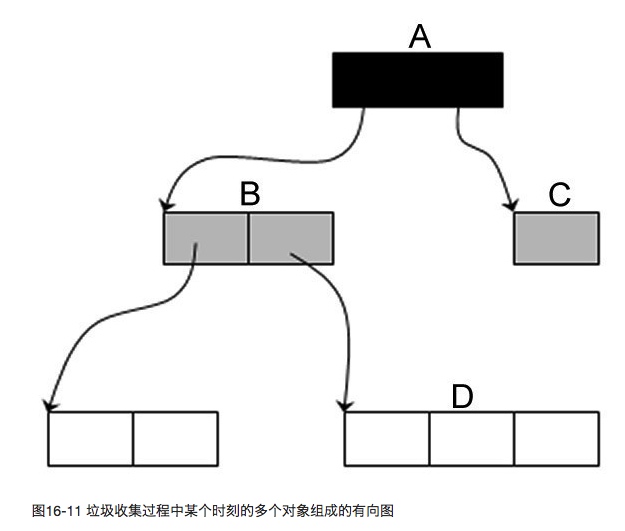
Python 中的标记清除
Python 的对象由三大部分组成,PyGC_Head,PyObject_Head 和本体。其中 PyObject_Head 里存计数器用来标记当前节点是否可回收,但是对于循环引用的情况,就需要 PyGC_Head 里的 refs,python 会根据一些触发条件进行三色模型的标记,某个对象的「可达次数」标记在 PyGC_Head 里,当这个可达次数为 0 时,代表对象不可达,也就需要回收之。PyGC_Head 之间有一条双向链表连接了所有对象,将他们纳入内存回收管理系统里。
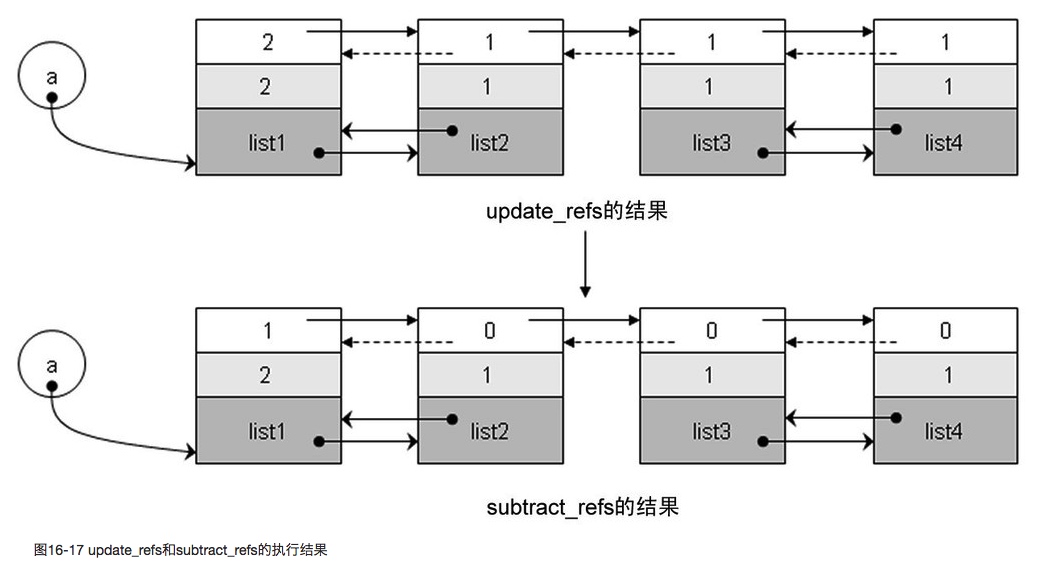
流程
- 在垃圾收集的第一步,就是遍历可收集对象链表,将每个对象的 gc.gc_ref 值设置为其 ob_refcnt 值。
- 接下来的动作就是要将环引用从引用中摘除。
- 有一些 container 对象的
PyGC_Head.gc.gc_ref还不为 0,这就意味着存在对这些对象的外部引用,这些对象,就是开始标记 - 清除算法的 root object 集合。
分代回收
这种以空间换时间的总体思想是:将系统中的所有内存块根据其存活时间划分为不同的集合,每一个集合就称为一个“代”,垃圾收集的频率随着“代”的存活时间的增大而减小,也就是说,活得越长的对象,就越可能不是垃圾,就应该越少去收集。
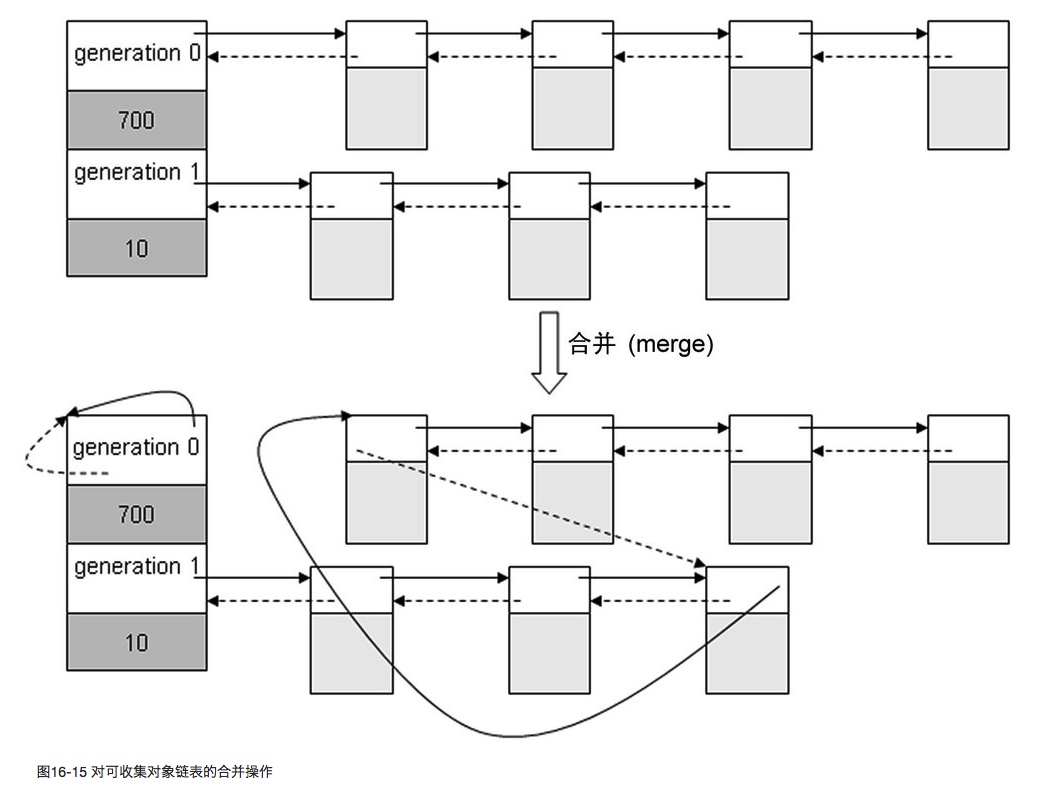
Python 采用了三代的分代收集机制,如果当前收集的是第 1 代,那么在开始垃圾收集之前,Python 会将比其“年轻”的所有代的内存链表(当然,在这里只有第 0 代)整个地链接到第 1 代内存链表之后,这个操作是通过 gc_list_merge 实现的。
总结
- 将比当前处理的“代”更年轻的“代”的链表合并到当前“代”中
- 在待处理链表上进行打破循环的模拟,寻找 root object
- 将待处理链表中的 unreachable object 转移到 unreachable 链表中,处理完成后,当前“代”中只剩下 reachable object 了
- 如果可能,将当前“代”中的 reachable object 合并到更老的“代”中
- 对于 unreachable 链表中的对象,如果其带有
__del__函数,则不能安全回收,需要将这些对象收集到 finalizers 链表中,因此,这些对象引用的对象也不能回收,也需要放入 finalizers 链表中 - 处理弱引用(weakref),如果可能,调用弱引用中注册的 callback 操作
- 对 unreachable 链表上的对象进行垃圾回收操作
- 将含有
__del__操作的实例对象收集到 Python 内部维护的名为 garbage 的链表中,同时将 finalizers 链表中所有对象加入 old 链表中
注意,如果对象拥有__del__方法,就不能通过垃圾回收来自动回收,所以要慎重使用这个方法。