《Python源码剖析》第一部分——Python对象基础
Python 的对象初始化
在 Python 中,对象就是为 C 中的结构体在堆上申请的一块内存,一般来说,对象是不能被静态初始化的,并且也不能在栈空间上生存。唯一的例外就是类型对象,Python 中所有的内建的类型对象(如整数类型对象,字符串类型对象)都是被静态初始化的。
python 的对象不像 C 是分配在栈、堆、data segment 等位置,而是全部分配在堆上!只有 python 内置类型在初始化时候才是被 C 语言层静态初始化。
PyObject 内部就两样:引用计数器、类型对象指针。
类型对象的定义:
typedef struct _typeobject {
PyObject_VAR_HEAD
char *tp_name; /* For printing, in format "<module>.<name>" */
int tp_basicsize, tp_itemsize; /* For allocation */
/* Methods to implement standard operations */
destructor tp_dealloc;
printfunc tp_print;
……
/* More standard operations (here for binary compatibility) */
hashfunc tp_hash;
ternaryfunc tp_call;
……
} PyTypeObject;
PyObject_VAR_HEAD是可变类型的头信息,其中除了PyObject_HEAD的内容外,额外添加了一个代表该对象元素数量的整型。从上边代码可见,python 的类型也是一个可变对象。
Python 的多态
Python 中所有类型在初始化后,在 C 语言层面都使用同一种指针PyObject *,所以 python 实现多态就非常容易。任何函数的参数都是一个 PyObject 类型指针,也就不存在编译器需要判断函数参数类型。
Python 对象内存池
Python 为了避免频繁的释放对象,采用了内存池的机制,在对象引用计数为 0 时,不会释放内存,而是将内存交还给内存池供 python 重新分配使用。每一种 python 类型,都有特定的内存池机制。
整数对象
-5 至 257 之间的小整数,存储在「小整数数组」里,这个数组 Python 自动创建,每次创建一个小整数,就指向这个数组里对应的 PyIntObject 值并把 PyIntObject 的计数加 1。(因此在-5 到 257 之间的数实际指向同一片内存空间,整数-5 和-5 的内存地址肯定是一样的)
大整数则由一个叫block_list的链表管理,每次分配一个大整数就在free_list(一个指向空闲内存 block 的指针)里拿出一个节点并把free_list后移一个block。关于free_list是如何把尚未分配的内存和已被释放的内存链接起来的,可以参见书中 113 页的插图理解。
值得注意的是,python 用于分配给整型的堆内存是不会自行销毁的,而是不断复用。也就是说,同一时间如果同时使用的整型太多,会消耗大量内存,并且这些内存在 python 关闭之前一直被 python 持有着。
字符串对象
typedef struct {
PyObject_VAR_HEAD
long ob_shash;
int ob_sstate;
char ob_sval[1];
} PyStringObject;
在 Python 源码中的注释显示,预存字符串的 hash 值(为了节省字符串比较的时间)和这里的 intern 机制将 Python 虚拟机的执行效率提升了 20%。
intern 机制 将新建的字符串缓存在一个 PyDictObject 里,相同的字符串共用同一内存。
单一字符的字符串,除了用 intern 缓存外,还会缓存在系统自带的一个字符串缓冲池里:
static PyStringObject *characters[UCHAR_MAX + 1];
+操作符和join的效率问题 +连接 n 个操作符会创建 n-1 次临时空间,join会直接处理一个 list 里的字符串,只分配一次内存。节省开销。
列表对象
参见 C++ vector 对象的存储方式。
字典对象
Python 使用散列表(时间复杂度 O(1))而非红黑树(时间复杂度 O(logN))来存储 map 结构。
**Hash 冲突(碰撞)**不同的值映射到相同的键时,就产生了冲突。一般解决办法有:
开链法(哈希桶):
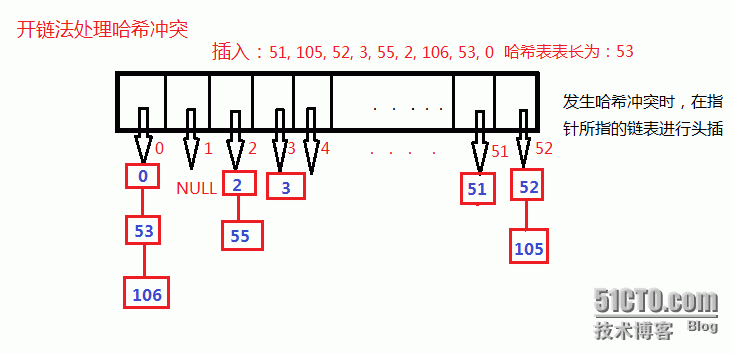
开放定址法: hash 一次没有命中就再 hash 一次,直到找到为止……(二次探测)
小于 8 个元素的 Dict,python 使用 PyDIctObject 内部的 smalltable 数组保存元素内容。
PyDictObject 对 String 类型的 key 做了特殊对待——简化了计算 hash 函数的过程(正常情况下 key 值是一个PyObject *对象,需要做大量类型判断,但是对 PyStringObject 就省了)。
**装载率(使用的空间/预先分配的空间)**大于 2/3 时,hash 冲突的概率会急速升高,这时 python 就会动态分配更多的空间。与其他类型一样,如果装载率太小,也会自动缩减分配的空间。
在确定新的 table 的大小时,通常选用的策略是时新的 table 中 entry 的数量是现在 table 中 Active 态 entry 数量的 4 倍,选用 4 倍是为了使 table 中处于 Active 态的 entry 的分布更加稀疏,减少插入元素时的冲突概率……所以当 table 中 Active 态的 entry 数量非常大时,Python 只会要求 2 倍的空间,这次又是以执行速度来交换内存空间。
注意这段话,执行速度和内存大小是反比关系,划分的空间越大,执行一次查找就越费时,所以分配的内存空间不是越大越好。
PyDictObject 也使用了同 PyListObject 一样的缓冲池方式。参考列表对象部分内容。
笔者总结:从上面的各种类型的处理规律可以总结出 Python 遵循的原则:小变量缓存,大变量尽量整块分配内存,回收变量时不释放内存而是尽量复用,预分配的空间既要满足需要又不能太大(太大就缩减)