与AI协作编程──测试篇
未来的程序开发范式,将是人与 AI 协作编程。这已经是软件行业不争的事实。像 Windsurf,Cusor,Copilot 之类的编程工具一方面提高了开发效率,另一方面也让代码变得更黑盒,更不易阅读和维护。
我试图浅显地讨论一下哪些软件开发的手段更适合在 AI 时代提高 AI 编写代码的可观测性和维护性。接下来所有以「与 AI 协作编程」为标题的文章都只是抛砖引玉,并未形成系统化方法论。期望任何错误之处,读者不吝赐教。
使用 AI 编写代码有哪些常见问题?
可观测性问题:AI 实现的功能不完备,经常要手动修改片段
AI 生成代码最大的问题在于,它经常引起人类不易察觉的隐蔽错误。当人类使用 prompt 修改代码时,由于 AI 行为的不易观测性,即便修复了一个 bug,也可能导致其他回归问题(引起已有逻辑的错误)。
上下文问题:缺少全局上下文,碎片代码之间缺少联系
由于 Token 数限制或经济上的考虑,很多编辑器会优化输入的内容,这就容易造成大模型错误地理解局部上下文。没有办法处理跨功能模块的业务逻辑。尤其项目变得庞大后,复杂的模块经常依赖其他模块,调整业务逻辑需要重构若干个代码文件。
解决思路
AI 编写代码的核心问题,可以归纳为不可观测性和缺少上下文造成的低维护性。为了解决这两个问题,我们需要先回顾一下传统软件工序如何让代码更易观测和维护。
人类主导的单元测试
单元测试是代码的说明书。复杂的业务逻辑通常需要阅读大量代码才能看懂。但是熟练的程序员会先看单元测试。好的单元测试会把模块的预期输入、输出完整地写进 Case 里。在 Unit Testing Principles, Practices, and Patterns 里,作者认为好的单元测试应该具备:
- 保护回归。即测试能够防止出现已经修复的问题在回归测试中复现的情况。
- 抵抗重构。即代码重构后,测试能正确识别出重构是否对已有功能造成影响。
- 快速反馈。即单元测试容易运行,发现问题能及时定位到错误。
- 易于维护。 测试不同于业务代码,它的可维护体现在正确处理依赖关系和共享代码。
这些原则最终目的,都是保证被测系统按预期行为运行。
当 AI 和人类合作完成代码时,我个人认为,在编写单元测试这件事上,人类应该主导(80%),AI 辅助(20%),因为单元测试定义了「我期望的行为」。
当单元测试完善后,又反过来指导 AI 实现的真正的业务代码。这时人类占比下降,AI 占据主导。人类反复运行单元测试,同时将测试结果和 prompt 一起传递给 AI,帮助 AI 修正程序的问题。
编写对 AI 友好的测试离不开好的模块设计
在编写好的测试时,也要关注正确的拆分模块。一个好的测试通常是给定输入,验证是否输出预期的结果。而模块如果依赖过多外部环境做分支判断,就会造成测试的输出严重依赖外部状态。这会降低模块的可观测性。
下面两条经验,可以帮助你写出好的代码:
写测试时要测试行为的结果,而不是步骤。写业务代码时,要 AI 写清步骤。
单元测试的「单元」可以不是一个类或函数。而是一组完成一个原子业务逻辑的操作。(当然也有不同的流派支持以类为单位测试,但这不是本文的重点)。为了让 AI 生成的业务代码具有抗重构特性,要验证 AI 的行为结果,而不是验证每一个实现步骤。耦合测试代码和实现步骤会导致业务的修改破坏已有的测试,使得「期望的行为」要不断随着「具体的实现」来修改。
当 AI 开始写业务逻辑后,应该以步骤驱动的方式逐步实现,期间,人类可以针对某一步骤修正 AI 的代码逻辑。但切忌破坏测试的逻辑。
无状态的代码(函数式)最容易测试
因为它的输出具有不变性。应该让核心代码尽量无状态,将状态、外部系统依赖放在应用服务层。而把深且不易理解的核心逻辑,放在领域服务层。这里的细节可以参考 DDD(Domain Driven Design)的思想。
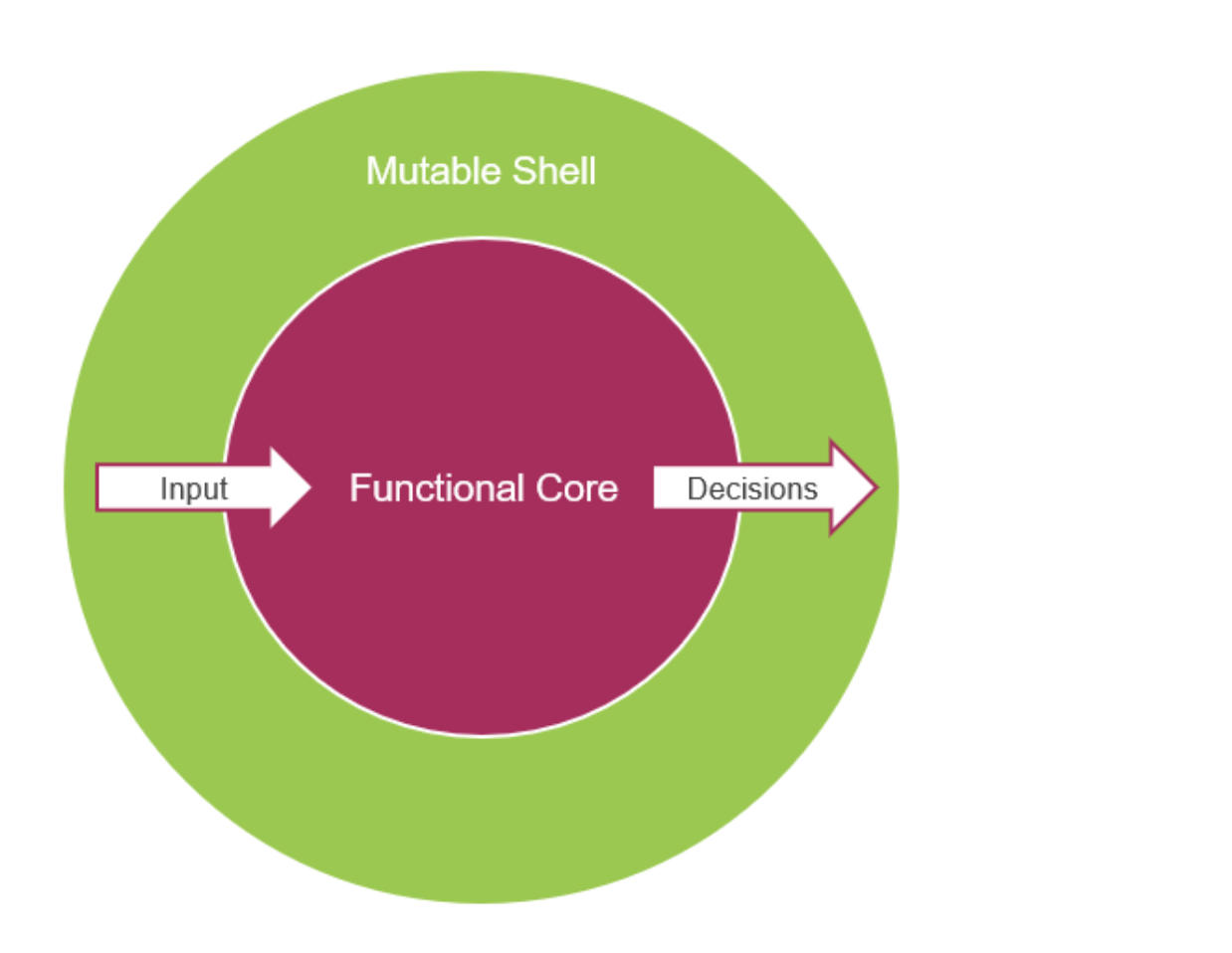
functional_core.png
小结
这篇文章作为一系列人类与 AI 协作编程话题的开头,从测试角度试图缓解 AI 生成代码的可观测性问题。
在后边的文章里,我希望从架构设计角度,讨论一下如何设计 AI 友好的、易于维护上下文的架构。
文章内容会随着时间的推移,持续更新,欢迎讨论。