DeepWIKI 是如何工作的
DeepWIKI 是一个从源代码仓库生成详细文档的 AI Agent 项目,由 Devin.ai 提供。自从它火了以后,我就一直非常好奇它是怎么工作的。
我梳理了网上的相关资料和一些开源项目,得到了相对清晰的工作流程。对于其中难点的部分,我会在后续文章中跟进我的发现。
生成代码结构地图
首先 DeepWIKI 本质是一个 RAG 系统,它读取源代码仓库作为输入,将代码进行语法分析之后转换成代表语法结构和文件结构的元数据和代表代码描述和片段的向量数据两部分,元数据存到关系数据库中,同时将对应的代码片段存储到向量数据库中以便后续 LLM 检索。
生成 WIKI 页面
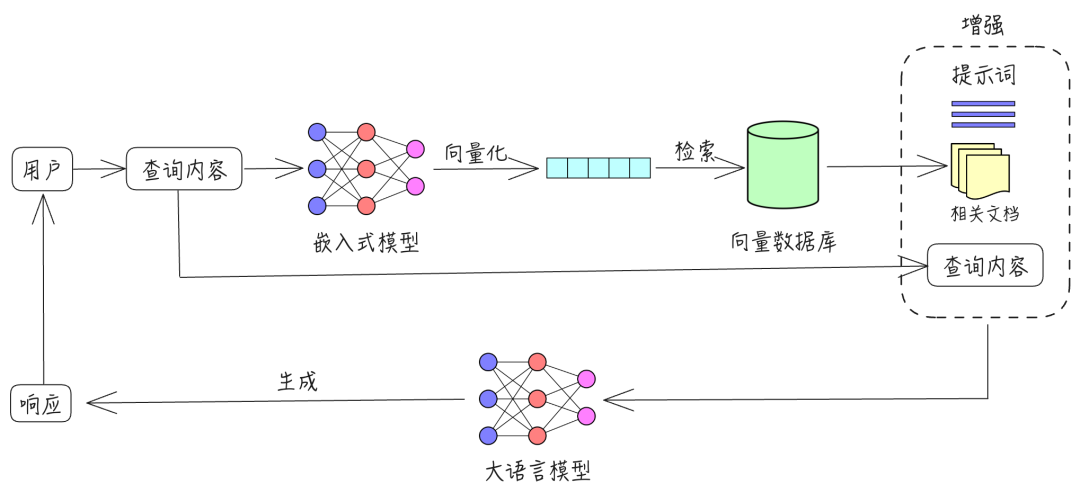
生成 WIKI 页面的过程,就是 RAG 系统 query 的过程:
- 程序递归读取项目结构。
- 从元数据库中查询当前文件的元数据,再从向量数据库中查找相关性最强的代码和描述信息的 id。
- 用这些 id 再去元数据库里查询到描述信息,从工程文件中查询对应代码片段。
- 将上面的所有内容作为 context,根据元数据类型(架构、组件等)组合适当的 prompt,输入给 LLM。
- 最后由一个前端渲染引擎把 LLM 的输出渲染成文档页面。
- 重复步骤 1。
难点 1:分块策略
上述过程中,如何在嵌入(embedding)前给代码分块,是个比较值得研究的话题。一般自然语言的分块是基于段落、句子、标点符号等方式,拆分出来的 chunk 包含完整的句子或者段落上下文。
但是代码的拆分不同,比如一个函数体由{ }包裹起来,如果使用自然语言的分词器分词,会导致上下文被拆分到不同 chunk 中,后续检索向量时准确度就会下降。
目前的解决办法有两种,一种是基于整个文件的分块,这种情况文件大小不能超过分块大小的上限,而且分块数据缺少真实的调用关系上下文。我们知道,代码的组织单元并不是文件(文件树只是方便人类阅读的组织形式),而是以类和函数为单元的网状依赖关系图。
第二种方式就是先用语法工具对代码文件做静态分析,再根据分析结果将代码以语法结构进行拆分。这种方式实现复杂,网上并没有找到相关的资料,幸而读到这篇RAG for a Codebase with 10k Repos,它介绍了如何利用语法静态分析来给代码分块,构建高效的代码仓库 RAG 系统。 但是文章也没有提供开源实现,考虑到作为商业项目的核心技术,这部分内容非常值得深入。我会持续跟进这部分内容的研究。
难点 2: 解析语法结构
元数据的语法解析要比向量数据简单一些,我从另一个开源项目Repo Graph中找到一些线索。
这个项目使用了 tree-sitter 来分析项目语法结构,从而得到三类元数据文件:
tag.json:代表一个文件、函数、类的路径、行号、描述等基础信息。tree_structure.json: 项目的文件树结构信息。*.pkl: 对象依赖关系图。
*.pkl是语法分析器扫描项目文件之后得到的一个网状的对象关系图,它使用 python 的 pickle 库把 python 网状对象序列化成文件。
从这个项目的实现来看,难点 1 中嵌入向量的过程似乎也可以用 tree-sitter 生成的代码元信息对代码按行分块。
提示词工程
在 RAG 查询阶段,要根据当前元信息的类型,组装不同的提示词。
这个项目Agent as a Judge 里有不少提示词可供参考:
生成概述的提示词
Provide a concise overview of this repository focused primarily on:
* Purpose and Scope: What is this project's main purpose?
* Core Features: What are the key features and capabilities?
* Target audience/users
* Main technologies or frameworks used
生成架构文档的提示词
Create a comprehensive architecture overview for this repository. Include:
* A high-level description of the system architecture
* Main components and their roles
* Data flow between components
* External dependencies and integrations
生成组件文档的提示词
Provide a comprehensive analysis of all key components in this codebase. For each component:
* Name of the component
* Purpose and main responsibility
* How it interacts with other components
* Design patterns or techniques used
* Key characteristics
* File paths that implement this component
其余请参考项目文件,就不一一列举了。
总结
DeepWIKI 是一个基于 RAG 系统的代码文档生成工具,它通过以下步骤工作:
- 对代码仓库进行语法分析,生成元数据和向量数据
- 然后通过 RAG 系统查询这些数据来生成文档
- 最后用前端引擎渲染成可读的文档页面
实现过程中有两个主要难点:
- 代码分块策略:需要考虑代码的语法结构,不能像自然语言那样简单分割
- 语法结构解析:可以使用 tree-sitter 等工具来解析代码结构
虽然目前有一些开源项目可以参考,但核心的分块策略实现仍然需要深入研究。