【译文】每个 AI 工程师都应该知道的 20 个循环设计模式

原文:20 Loop Design Patterns Every AI Engineer Should Know
作者:Rahul (@sairahul1)
声明:本文由 AI 翻译,可能包含错误
大多数 AI 工程师知道如何构建一个 agent。
但很少有人知道如何构建一个能在首次尝试后不断变好的系统。
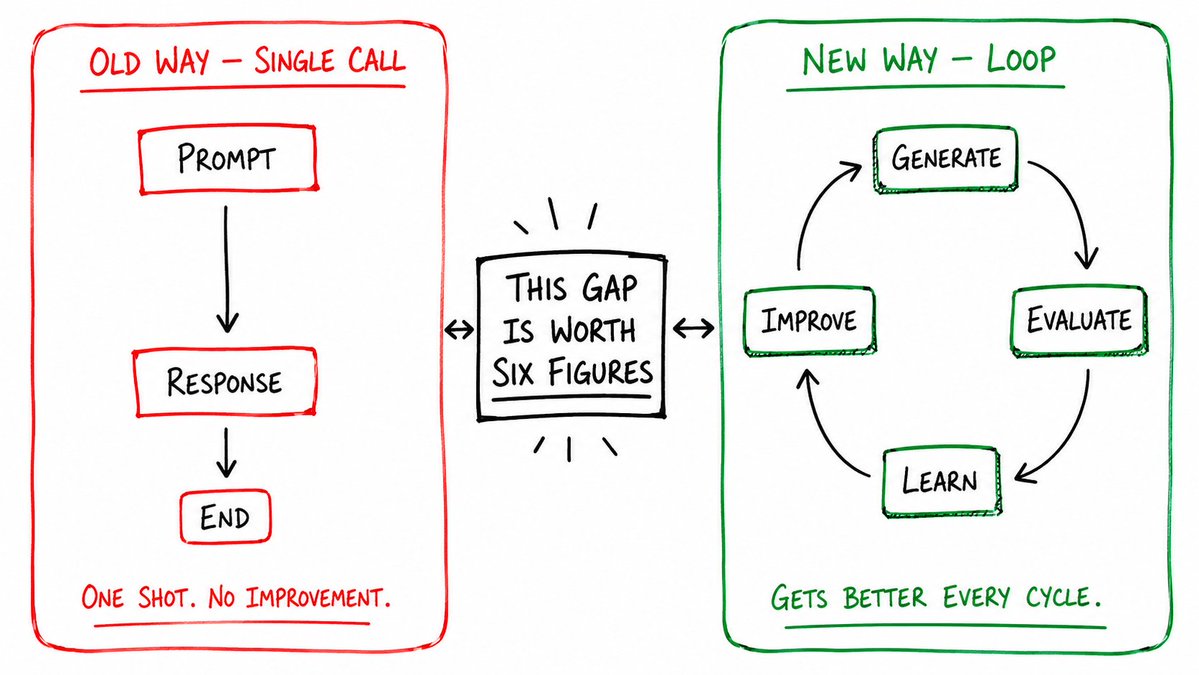
这个差距值六位数美金。
区别在哪里:
Agent 是一个工人。
Loop(循环)是让工人进步的机制。
当今生产环境中最强大的 AI 系统,不是单次模型调用。
它们是循环。
生成 → 评估 → 学习 → 改进。
一遍又一遍。
直到输出真正变好。
以下是生产级 AI 系统中反复出现的 20 个循环设计模式。
收藏这篇文章。你会用到它们的。
Agent vs Loop
旧方式:Prompt → Response → Done。
新方式:Generate → Critique → Rewrite → Score → Retry → Remember → Improve。
一个是流水线工人,做一次就完事。
另一个是流水线工人,研究每一个错误,重写操作手册,每个班次进步 3%。
现在能交付生产级 AI 的团队,他们不是在写更好的 prompt。
他们在构建更好的循环。
类别 1 — 质量改进循环(让输出在离开系统前就变好)
1. Generate → Critique → Rewrite
AI 工程中最重要的循环。
生成输出。评论家审阅。生成器根据反馈重写。重复直到质量达标。
不是一个模型。两个角色。一条流水线。
[Generator] → 初稿
[Critic] → "第三段含糊不清,缺少证据,语气不对"
[Generator] → 根据批评重写
[Critic] → "好多了,但结尾还是薄弱"
[Generator] → 最终重写
适用于:写作、代码审查、报告、策略文档、销售邮件。
洞察:负责生成的模型不是自己输出的最佳评判者。
独立的评论家每次都能发现生成器遗漏的问题。
2. Score-and-Retry Loop
生成。打分。低于阈值就重试。
简单。强大。被严重低估。
score = evaluate(output)
while score < threshold:
output = generate(prompt)
score = evaluate(output)
attempts += 1
if attempts > max_retries:
return best_so_far
最适合质量可衡量的场景——提取准确率、格式合规性、事实正确性、线索评分。
生成器不知道自己在被评分。
评估者知道。
这个分离就是模式本身。
3. Multi-Critic Loop
一个评论家有盲点。
那就用四个。
- 正确性评论家:事实准确吗?
- 风格评论家:清晰且文笔好吗?
- 安全评论家:合适且安全吗?
- 领域评论家:符合专业标准吗?
每个独立评估。
最终输出必须同时满足四个才能放行。
用于:医疗 AI、法律文档审查、金融分析、受监管内容。
4. Adversarial Critique Loop
评论家唯一的任务是打破这个答案。
不是改进它。是打破它。
对抗性评论家会问的问题:
- 这里什么假设会失效?
- 缺少什么证据?
- 怀疑论者会说什么?
- 什么地方自信地错了?
生成器随后要么辩护,要么重写。
最好的答案在攻击中存活下来。
用于:研究综合、投资论点评审、战略规划、风险分析。
5. Judge Ensemble Loop
一个评委打分有噪声。
五个评委平均掉噪声。
将同一个输出送进多个评估器。
汇总分数。
只有高共识的输出才晋级。
用于:单一模型评估不可靠、风险高、边界情况重要的场景。
类别 2 — 记忆循环(从发生过的事情中学习)
6. Reflexion Loop
这是最重要的自我改进模式,没有之一。
Agent 失败。Agent 分析失败原因。Agent 存储教训。Agent 带着教训重新尝试。
每一次迭代都比上一次更聪明。
attempt 1: 失败
reflection: "我以为 X 是对的,但 X 是错的。下次先验证 X。"
attempt 2: 融入教训 → 部分成功
reflection: "好多了。但我跳过了 Y。加上 Y 检查。"
attempt 3: 成功
一个系统"失败一次"和"只失败一次"之间的区别。
7. Memory Update Loop
每次任务完成后存储三样东西:
- 做了什么决定
- 结果是什么
- 下次会怎么不同做
未来的运行继承这些知识。
第 6 个月的系统已经不是第 1 个月的那个系统了。
它读了 6 个月的自己历史。
8. Error Library Loop
存储每一次失败。
错误答案。糟糕输出。执行失败。边界情况。
在处理新任务之前:
先搜索错误库。
如果类似的失败存在 → 在开始之前就应用已知修复。
系统不再重复犯同一个错误。
这是生产级 AI 中最被低估的模式。
9. Success Pattern Loop
大多数工程师只存失败。
也要存成功。
当任务顺利时:
- 保存方法
- 保存上下文
- 保存什么让它奏效
遇到类似任务时检索成功模式。
从胜利中学习,而不仅仅是错误。
10. Memory Compression Loop
记忆永远在增长。
无限记忆 = 不可用的记忆。
当积累到 N 条之后:
压缩它们。
将许多具体记忆 → 变成少数高层抽象。
压缩前:
"任务 A 因为 X 失败了"
"任务 B 因为 X 失败了"
"任务 C 因为 X 失败了"
压缩后:
"模式:X 导致失败。总是先检查 X。"
上下文保持可控。模式保持可访问。系统保持快。
类别 3 — 规划循环(当现实变化时调整计划)
11. Plan → Execute → Replan
AI Agent 设计中最常见的错误:
把计划当作固定的。
计划在接触现实时会破裂。
模式:
制定计划 → 执行步骤 → 观察结果 → 更新计划 → 继续
不是瀑布。
是螺旋。
每一圈收紧方法。
用于:环境变化、任务有依赖关系、长期目标。
12. Dynamic Workflow Loop
大多数流水线是固定的。
Step 1 → Step 2 → Step 3。永远如此。
动态工作流根据结果改变:
如果输出 A → 走分支 X;如果输出 B → 走分支 Y;如果输出 C → 跳到步骤 5。
流水线在运行时决定自己的形状。
用于:多文档研究、客服路由、自适应内容流水线。
13. Goal Decomposition Loop
大目标进入。
系统分解为子目标。
每个子目标分解为任务。
每个任务分解为步骤。
持续分解直到每个单元小到一次调用可以完成。
目标:"写一份全面的竞争分析"
↓
子目标 1:"识别前 5 名竞争对手"
子目标 2:"分析每个竞争对手的产品"
子目标 3:"对比定价模式"
子目标 4:"识别差距"
↓
每个子目标 → 任务 → 单独的模型调用
循环持续分解,直到系统可以行动。
14. Progress Evaluation Loop
每 N 步:停下来问:
“我们真的在接近目标吗?”
如果是:继续当前策略。 如果不是:改变策略、工具或计划。
系统监控自己的进度。
而不是盲目执行。
用于:长时间运行的研究 agent、多天自主任务、调试 agent。
15. Constraint Satisfaction Loop
持续运行直到所有约束被满足。
while not all_constraints_satisfied(output):
output = improve(output, unsatisfied_constraints)
constraints = [
budget_under_limit,
quality_above_threshold,
latency_under_200ms,
tone_matches_brand,
no_hallucinations
]
在生产系统中非常常见。
输出在每一条业务规则通过之前都不算完成。
类别 4 — 探索循环(通过尝试多条路径找到最佳答案)
16. Branch-and-Explore Loop
不要只走一条路。
同时探索多条路径。
paths = [
generate(approach="conservative"),
generate(approach="aggressive"),
generate(approach="creative")
]
scores = [evaluate(p) for p in paths]
best = paths[scores.index(max(scores))]
对比结果。选择最佳分支。丢弃其余。
用于:内容变体、架构决策、多假设调试、A/B 生成。
17. Tree Search Loop
Branch-and-Explore 只深入一层。
Tree Search 需要多深就走多深。
扩展最有希望的节点。剪掉最弱的。持续探索直到找到解。
root → [A, B, C]
A → [A1, A2] # A 看起来有希望,扩展它
B → prune # B 太弱,停在这里
A1 → [A1a, A1b]
A1a → solution ✓
用于:复杂推理链、多步规划、代码调试、研究综合。
计算成本高,但能找到单次调用无法找到的解。
18. Debate Loop
两个 agent。一个话题。相反的立场。
Agent A 为答案辩护。Agent B 反对它。
每一轮挑战假设、要求证据、暴露逻辑漏洞。
最终答案通过分歧产生。
不是通过一致。
对抗性压力能发现自信的单 agent 答案遗漏的东西。
用于:投资决策、战略规划、风险评估、研究评论。
类别 5 — 系统优化循环(循环改进循环本身)
19. Prompt Optimization Loop
大多数工程师写一个 prompt 就不再碰它。
Prompt 优化循环改变了这一点。
系统:
- 在测试集上运行 prompt
- 对每个输出评分
- 识别 prompt 失败的地方
- 重写 prompt 修复这些失败
- 重新运行并重新评分
Prompt 自动变好。
不需要人碰。
current_prompt = "Summarize this document."
for iteration in range(max_iterations):
outputs = [run(current_prompt, doc) for doc in test_set]
scores = [evaluate(o) for o in outputs]
avg_score = mean(scores)
if avg_score >= target:
break
failures = [o for o, s in zip(outputs, scores) if s < threshold]
current_prompt = improve_prompt(current_prompt, failures)
用于:生产流水线、自动化内容系统、分类任务。
生产级 AI 中最好的 prompt 不是人写的。
它们是进化出来的。
20. Workflow Optimization Loop
这才是真正有趣的地方。
循环改进循环本身。
系统测量自己的性能:
- 延迟:每一步花了多久?
- 成本:每次调用用了多少 token?
- 质量:每个阶段的输出得分多少?
然后它修改自己的工作流。
太慢了?并行化两个步骤。 太贵了?在质量能保持的地方用一个更小的模型替换 GPT-4 调用。 质量下降了?在最终输出前加一个评论家。
metrics = measure_workflow(outputs, latency, cost)
if metrics.latency > target_latency:
workflow = parallelize(slow_steps)
if metrics.cost > budget:
workflow = replace_with_cheaper_model(high_cost_steps)
if metrics.quality < threshold:
workflow = add_critic_before(final_output_step)
这就是真正的自我改进系统的起点。
不只是输出在改进。
是系统在重新设计自己。
所有 20 个模式背后的统一模式
每一个循环都共享一个结构:
Act → Observe → Evaluate → Adjust
这就是完整的配方。
输出在第一次尝试时从来不是最终的。
输出是一个起点。
循环才是把起点变成生产级作品的东西。
全景图
类别 1 — 质量循环(让输出在离开前变好)
- Generate → Critique → Rewrite
- Score-and-Retry
- Multi-Critic
- Adversarial Critique
- Judge Ensemble
类别 2 — 记忆循环(从发生过的事情中学习) 6. Reflexion 7. Memory Update 8. Error Library 9. Success Pattern 10. Memory Compression
类别 3 — 规划循环(当现实变化时适应) 11. Plan → Execute → Replan 12. Dynamic Workflow 13. Goal Decomposition 14. Progress Evaluation 15. Constraint Satisfaction
类别 4 — 探索循环(通过尝试多条路径找到最佳答案) 16. Branch-and-Explore 17. Tree Search 18. Debate
类别 5 — 系统优化循环(循环改进循环) 19. Prompt Optimization 20. Workflow Optimization
大多数工程师认为 agent 是未来。
Agent 只是工人。
循环才是让工人进步的东西。
AI 领域正在发生的最大的转变不是更好的模型。
是从 Prompt → Response
转向 Generate → Evaluate → Learn → Improve
掌握循环设计的团队不会写出更好的 prompt。
他们会构建出每天都在变好的系统。
部署之后,不需要任何人碰它们。