【译文】自主长时运行编程 Agent

原文:Autonomous Long-Running Coding Agents
作者:Elvis(@omarsar0),DAIR.AI Academy
声明:本文由 AI 翻译,可能包含错误
自主编程正从"更好的提示词"转向"更好的控制系统"。关键的转变在于,工程师们正在学习如何用目标、评估器、循环和工件来封装 Agent,让它们在人类停止输入后继续工作。
这很重要,因为大多数严肃的工程工作跨越很长的周期:模糊的需求、隐藏的约束、部分失败、不断变化的上下文、以及反复的验证。新的前沿是围绕 Agent 设计系统,让它能够规划、执行、检查自己的成果、从错误中恢复,并在没有持续人工操控的情况下持续取得进展。
这篇文章基于我在 DAIR.AI Academy 的一场有关自主长时运行编程 Agent 的分享,我在其中演示了 Claude Code 的 /goal 模式、较新的 /loop 命令、验证器、工件和编排模式的实际应用。本文与 Codex 和 Claude Code 协作完成。
从 Prompt 到 Goal 设计
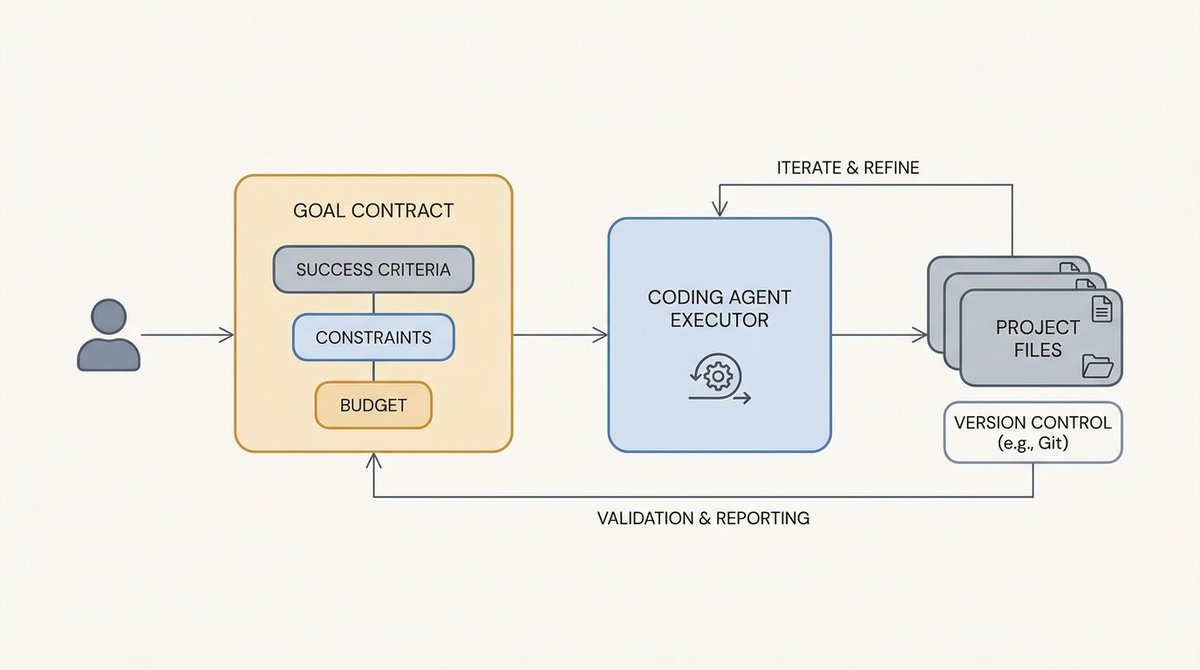
核心思路很简单:编程 Agent 仍然是执行者,但人类不再逐轮交互。人类改为指定期望的最终状态、证明成功的证据、不可违反的约束条件,以及在可能的情况下规定轮次和预算。
Goal 更像一份契约,而不是更长的提示词。一个弱的 Goal 给模型留出了提前停止、走捷径或重新定义成功的空间——它在对话记录中看起来合理,但在真实系统中会失败。强的 Goal 则给 Agent 一个可以持续自我衡量的目标。
工程判断力在这里仍然关键。最好的 Goal 包含了模型凭猜测可能遗漏的领域知识。对于一个研究实验,这可能是目标基准分数、留出评估集、要求的损失曲线、以及结果必须超过初始基线的规则。对于 UI 任务,可能是截图参照、具体的布局约束和浏览器验证步骤。模型负责执行,但人类仍然定义"完成"的真正含义。
评估器成为一等组件
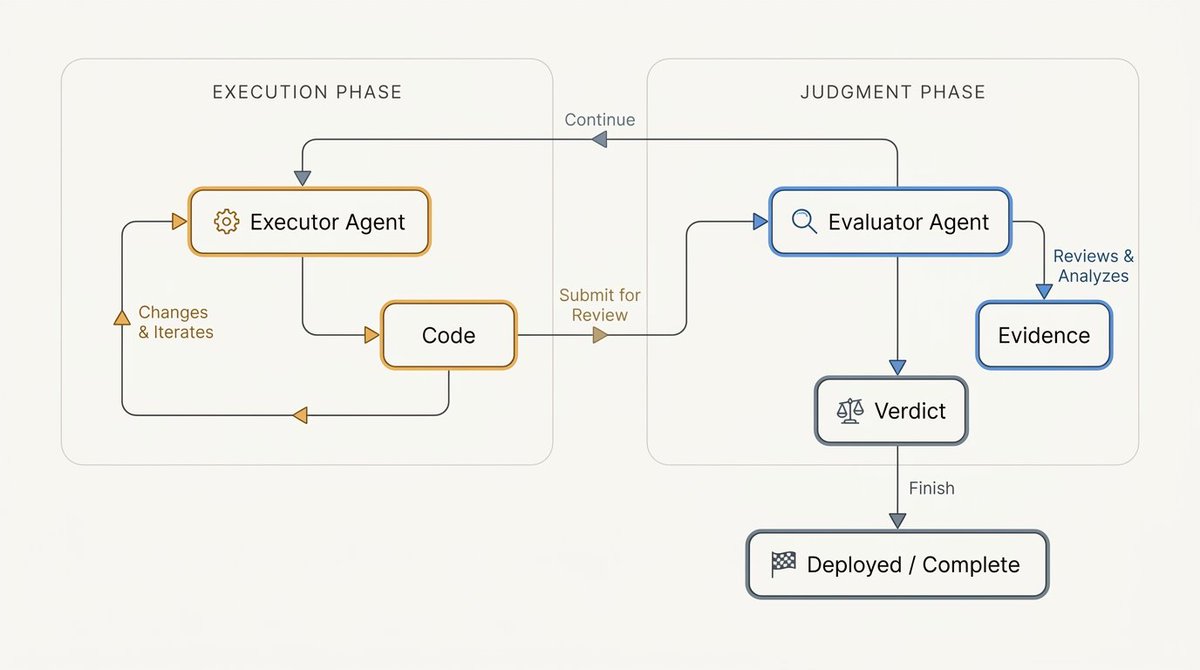
长时运行 Agent 除了目标之外,还需要第二个角色:评估器。它可以是一个编码 Agent、一个 LLM as Judge、一个脚本、一个测试套件、一个基准测试工具,或者它们的组合。关键设计决策是将评估器与任务匹配。当成功标准明确时,确定性检查更优。类型检查、单元测试、代码检查规则、集成测试和基准脚本——只要能清晰表达条件,就应该优先使用。
当成功标准模糊时,Agent 评估器就派上用场了。脚本能告诉你测试是否通过,但很难判断生成的研究报告是否连贯、实现是否忠实遵循论文、或 UI 是否匹配设计意图。这时评估器需要利用语言、判断力,有时还需要视觉能力。
实用的模式是:确定性检查作为地板,Agent 评估作为更高层次的审查。这种组合既减少了幻觉式的假成功,又保留了处理那些无法干净地塞进测试断言的任务的自主性。
验证器定义信任边界
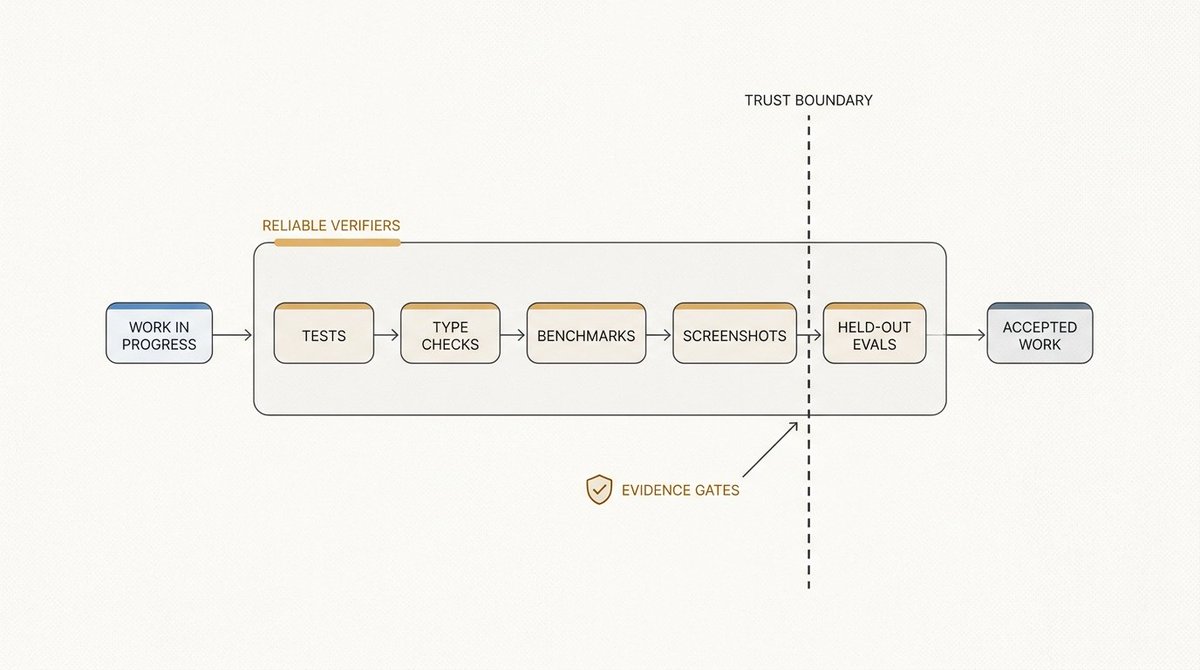
更深层的点是:自主性只有在系统拥有可靠的验证器时才有效。编程 Agent 可以生成计划、实现功能、解释为什么它认为工作已完成,但这个解释不应被视为证据。证据来自一个 Agent 无法轻易绕过的外部检查。
对于代码,验证器可能是测试套件、类型检查器、基准测试、浏览器运行、截图对比或可复现脚本。对于研究工作,可能是留出评估集、复现的表格、损失曲线或超过基线的基准分数。对于设计工作,可能是参考截图加上视觉审核步骤。验证器把一个长时间运行的 Agent——从自信的文本生成器——变成一个可以放心交给更多时间的系统。
大多数捷径就出现在这个边界上。如果验证器定义模糊,模型通常会满足任务的最简单解释。如果验证器定义过窄,模型可能会过度拟合它,而错失更广泛的意图。一个好的自主工作流需要分层验证:廉价的确定性检查捕获基本错误,更高级的审查处理需要判断力的错误。少数前沿模型已经能实现一定程度的验证,但基于我的研究,仍然存在明显的 OOD(分布外)问题——如果你分配给 Agent 的验证任务落在其训练分布之外,模型表现会很挣扎。
验证器仍是一个开放的研究方向,但我预计更多公司会开始重注这个方向。微调专用的验证器在企业中也需求旺盛。
循环让自主性持久
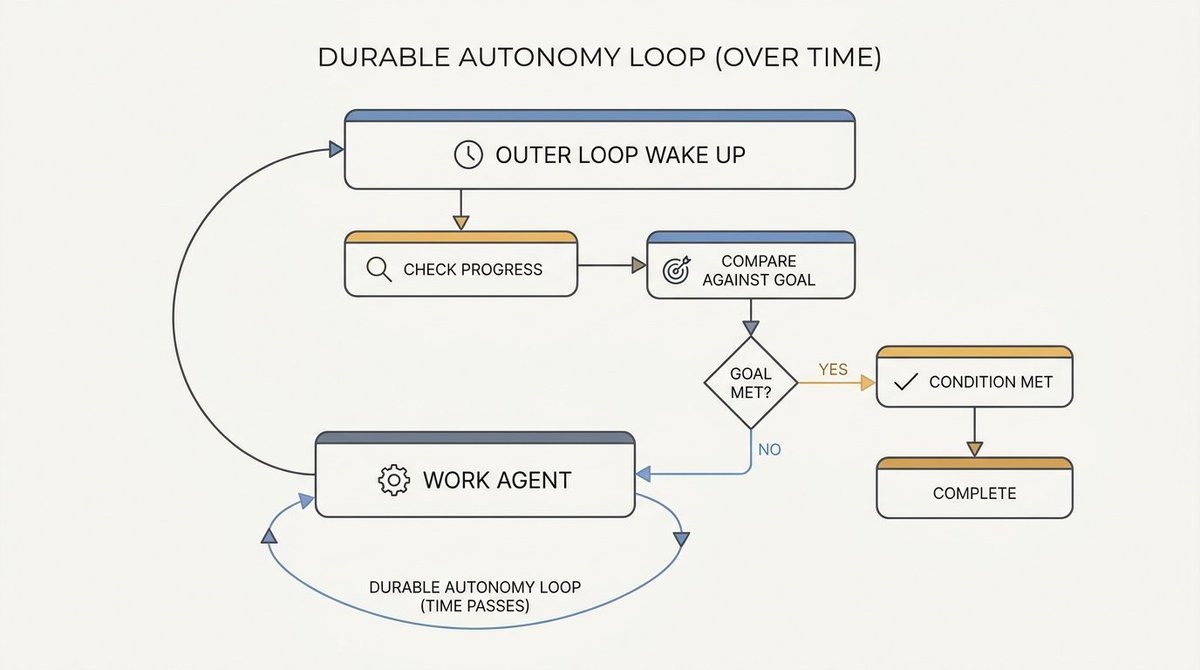
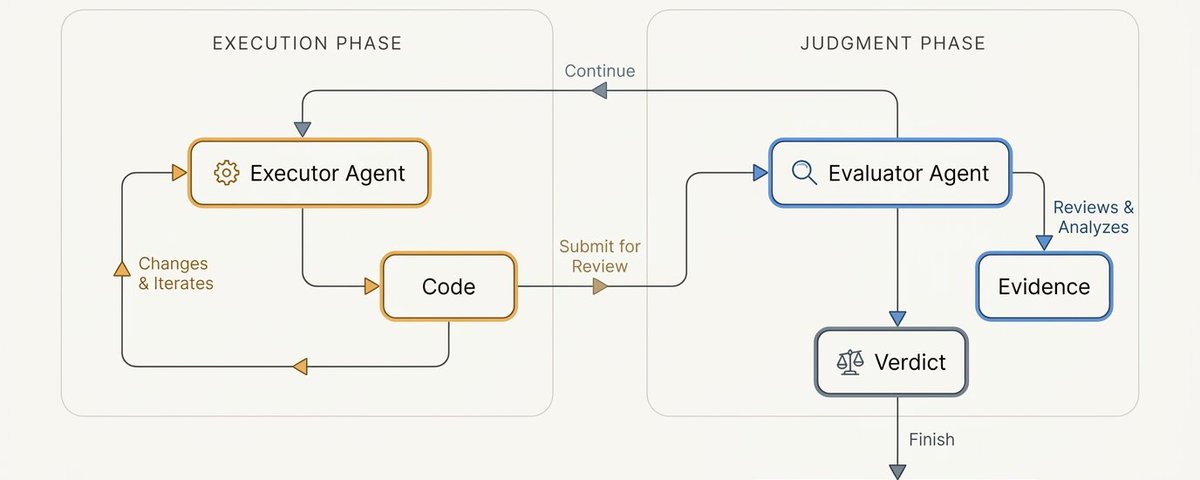
Goal 给 Agent 方向,但循环让工作保持活力。这个区别很重要,因为模型经常在真正任务完成之前就停下来。它们可能达到轮次限制、失去信心、耗尽上下文、或认为部分解已经足够。
循环是外层控制系统。它醒来、检查进度、运行检查、将结果与目标对比,当目标未达成时把 Agent 送回去,附上下一条指令。最简单的形式是 Ralph 循环模式——一个编码 Agent 加一个确定性条件。更灵活的形式是循环中包含一个评估 Agent,它能推理进度并决定下一步该做什么。
长时自主运行的本质是用外部控制层的监督下的反复尝试,而不是一次持续的智能行为。Agent 仍然会失败,但循环给了系统一个注意到失败并继续的机会,而不是静默宣布胜利。
规划还是靠人
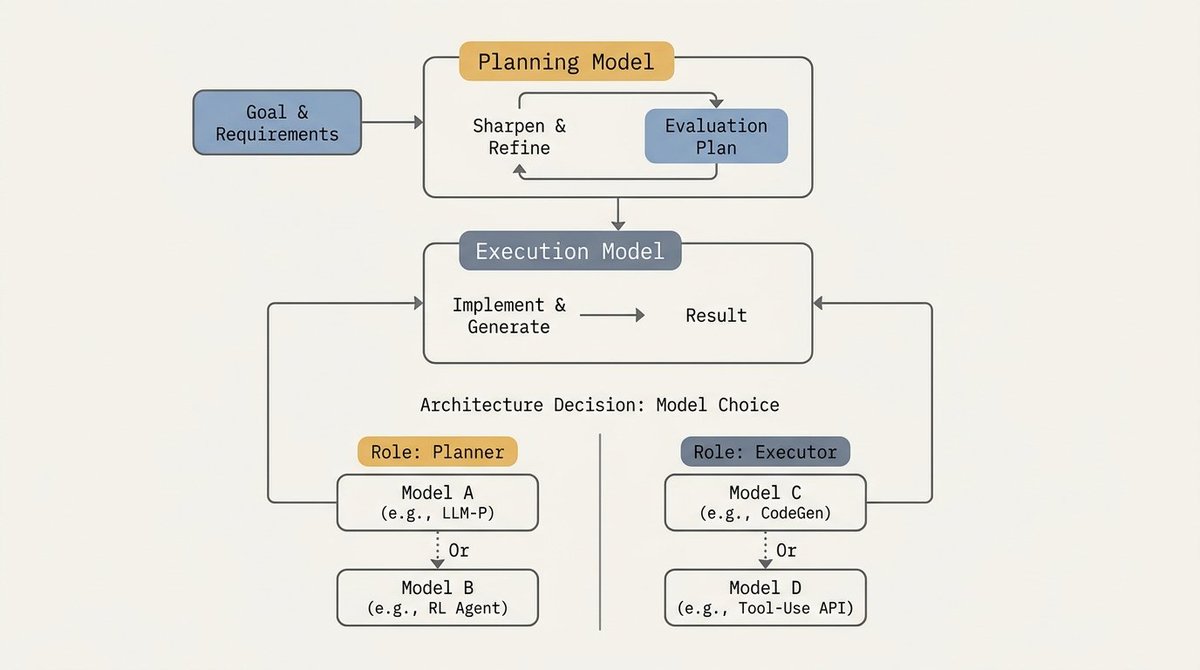
一个最强烈的结论是:规划仍然是关键。你可以让前沿模型生成计划,但在交给自主循环之前,你仍然需要检查它、挑战它的假设、让成功标准更清晰。
这引出了一种有用的分工。更强的规划模型可以帮助定义目标、识别遗漏的约束、构建评估体系。不同的执行模型在计划明确后运行实现。在实践中,这意味着工程师不应再将"模型"视为单一选择。模型选择变成了架构决策。
有些模型更擅长规划。有些更擅长执行。有些是更便宜的评估器。有些更擅长基于视觉的审查。一个好的编排器让你可以切换这些角色,而不是等待一家供应商提供完美的编程 Agent 界面。
可视化工件成为控制面板
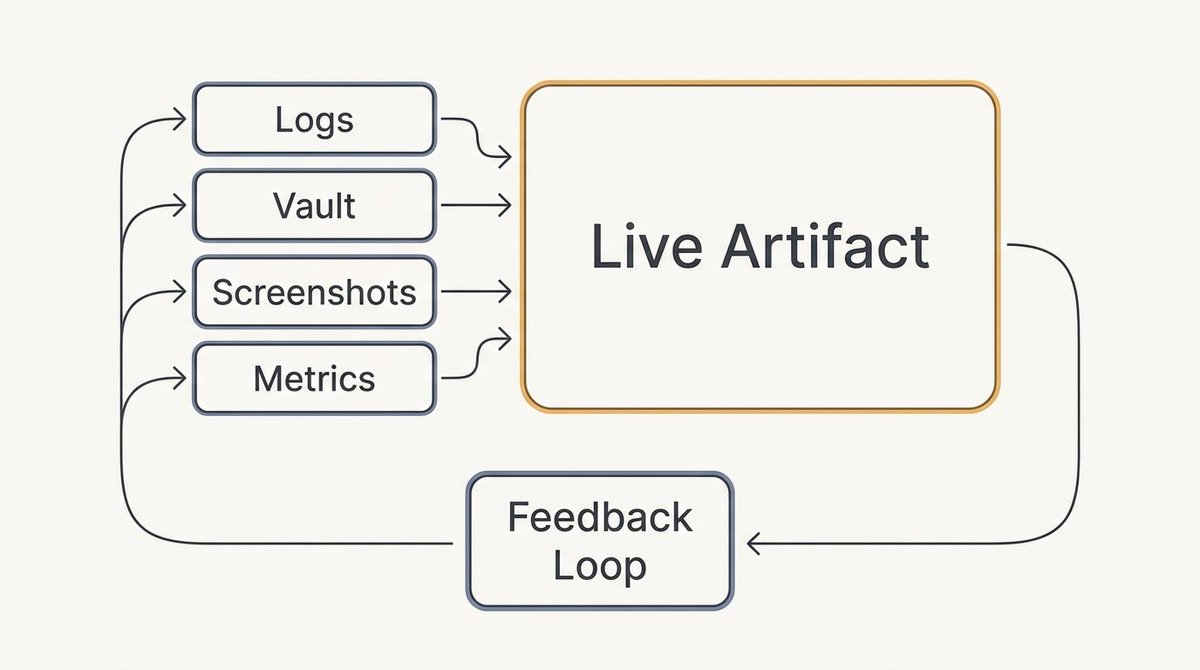
当多个 Agent 同时运行时,终端日志不可扩展。一旦你让几个会话并行工作,纯文本就成了理解进度的糟糕界面。
实时的可视化工件之所以重要,是因为一个包含损失曲线、基准分数、任务状态、截图、成本估算和近期决策的仪表板,让人类监督自主性变得容易得多。工件成为决定何时介入的控制面板,而不是事后生成的报告。
最有用的模式是将存储与呈现分离。Markdown 或知识库存储持久的证据、日志、笔记、计划和结果。HTML 工件将这些状态渲染成可视化、可交互的东西。Agent 可以搜索 Markdown,而人类可以监控工件。
对于 UI 和产品工作,视觉线索尤其强大。截图参照比文字更精确地传达设计意图,而具备视觉能力的评估器可以将实现与参照对比。这减少了常见的失败模式:Agent 技术上实现了所请求的组件,但忽略了间距、层级、对齐和产品手感。
Session 挖掘将使用转化为记忆
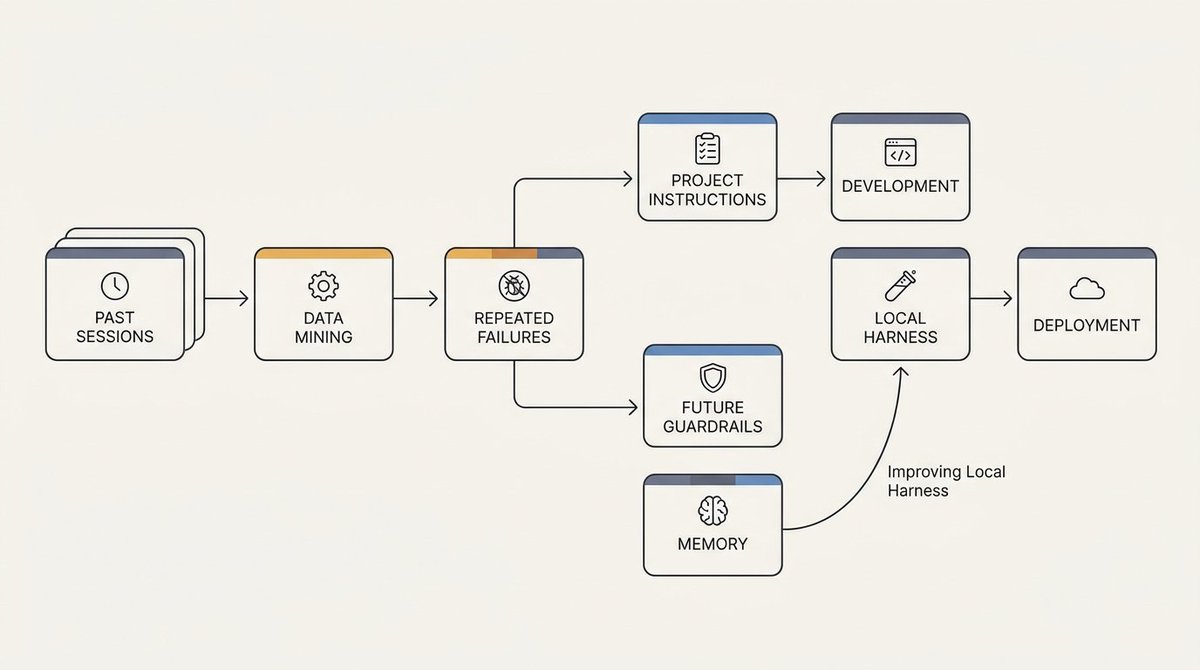
另一个重要洞察是:过去的 Agent 会话是丰富的工作流数据源。如果 Agent 反复以同样的方式失败、忘记跑同样的检查、用了错误的路径、或重试同一条坏掉的命令,这个模式不应该埋在日志里。
Session 挖掘将这些对话记录转化为操作规则。Agent 可以扫描过去三十天的工作,找到反复出现的失败模式,并提出更新项目指令、知识库经验或 Agent 规则的建议。这是团队在不从头训练模型的情况下逐步改进其工具链的方法。
目标是让本地环境变得更智能,而不需要从头训练模型。Agent 指令文件中的一条小规则就能防止跨未来会话的重复失败,尤其是当这条规则与项目特定相关时。
实际操作模型
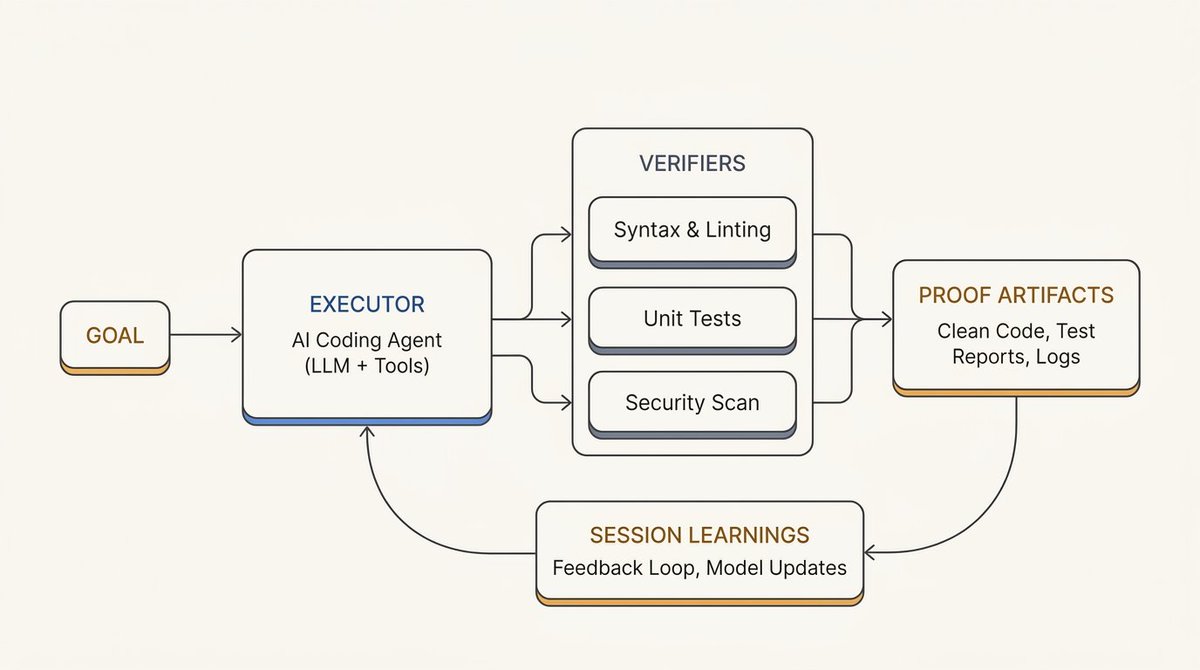
对于 AI 工程师而言,浮现的工作流如下:
- 在启动完整的自主运行之前,先在一个小的、便宜的子集上试验
- 用可衡量的成功标准、明确的约束条件和可能的轮次/时间预算来写 Goal
- 将执行器与评估器分离,使实现和判断不坍缩到同一个角色
- 在长时运行循环开始之前定义外部验证器
- 尽可能使用确定性检查,然后对模糊标准使用 Agent 评审
- 要求提供证据工件:日志、截图、基准曲线或变更文件
- 挖掘过去的会话,将反复出现的教训升级为项目指令
这就是使用编程 Agent 和设计自主编程系统之间的区别。前者给你一场对话。后者给你一套控制体系。
仍然存在的问题
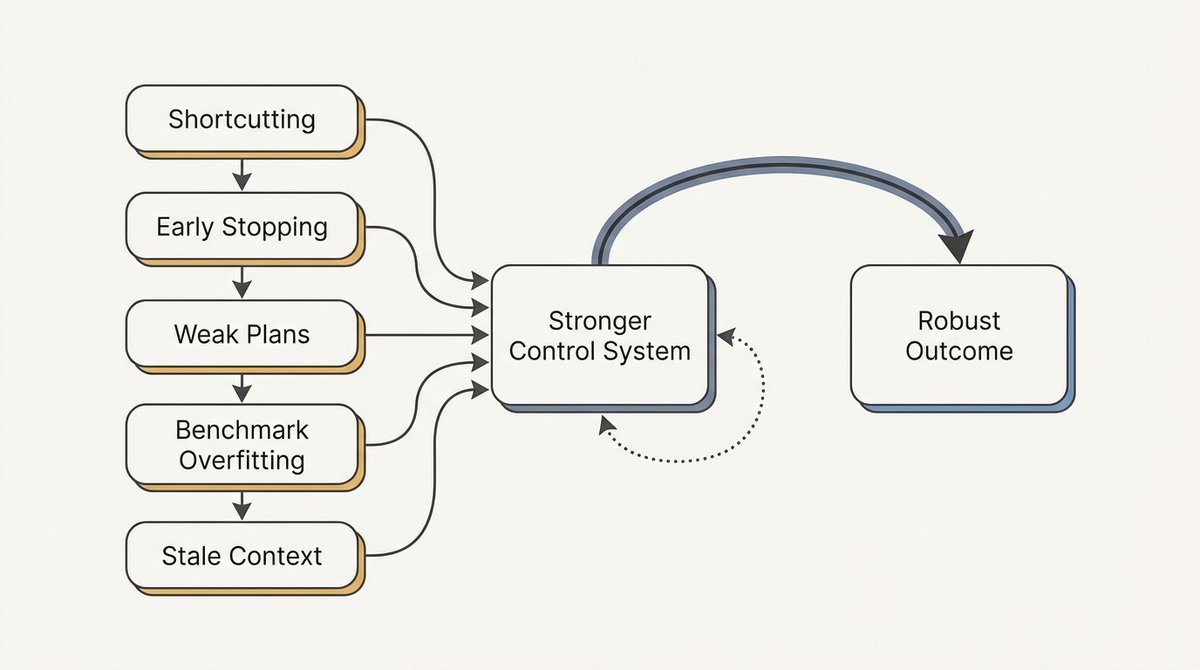
这些都没有消除硬问题。Agent 仍然走捷径。它们仍然提前停止。它们仍然高估完成度。它们仍然产生自信但薄弱的计划,尤其是在最近的论文、不熟悉的基准或训练分布之外的系统上。
给它们更多信任解决不了这个问题。更好的控制系统才做得到。目标、循环、评估器、确定性检查、可视化工件和会话记忆——都是让自主性可观察、可纠正的方法。
方向很清楚。编程 Agent 的未来取决于围绕更强大模型的更好的编排,工程师们设计出 Agent 可以安全运行数小时甚至数天、并产出可验证工作的条件。